OpenLDAP2.4管理员指南
小 (→Syncrepl细节) |
小 (→olcLogLevel:) |
||
| (未显示3个用户的50个中间版本) | |||
| 第4行: | 第4行: | ||
'''本文的英文原文来自[http://www.openldap.org/doc/admin24/index.html OpenLDAP Software 2.4 Administrator's Guide]''' | '''本文的英文原文来自[http://www.openldap.org/doc/admin24/index.html OpenLDAP Software 2.4 Administrator's Guide]''' | ||
| − | + | 先翻译快速开始指南和目录复制。 | |
| + | |||
| + | '''前言''' | ||
| + | |||
| + | ''版权'' | ||
| + | |||
| + | 版权所有1998-2008 ,[http://www.openldap.org/foundation/ OpenLDAP基金会],保留所有权利。 | ||
| + | |||
| + | 版权所有1992-1996年,[http://www.umich.edu/ 密歇根大学]的Regents,保留所有权利。 | ||
| + | |||
| + | 本文被视为OpenLDAP软件的一部分. 本文遵从[http://www.openldap.org/doc/admin24/copyright.html OpenLDAP软件版权声明]和[http://www.openldap.org/doc/admin24/license.html OpenLDAP公开许可]的第四款的条件. 完整的声明和相关的许可可以分别在附录K和L看到. | ||
| + | |||
| + | OpenLDAP软件和本文的一部分可能是来自其他各方和/或受到其他版权限制。单独的源文件应该有额外的版权声明。 | ||
| + | |||
| + | ''本文的范围'' | ||
| + | |||
| + | 本文为在UNIX (以及类似UNIX)系统上安装OpenLDAP 软件2.4版 (http://www.openldap.org/software/)提供一个指南. 本文的目标读者是基本了解基于LDAP的目录服务的有经验的系统管理员. | ||
| + | |||
| + | 本文件是用来与其他由软件包以及该项目的网站( http://www.OpenLDAP.org/ )上提供的OpenLDAP信息资源配合使用的。该网站的有很多来源. | ||
| + | |||
| + | '''OpenLDAP 资源''' | ||
| + | {|border="1" cellspacing="0" | ||
| + | !资源 !! URL | ||
| + | |- | ||
| + | |文档目录 || http://www.OpenLDAP.org/doc/ | ||
| + | |- | ||
| + | |常见问答解答 || http://www.OpenLDAP.org/faq/ | ||
| + | |- | ||
| + | |问题跟踪系统 || http://www.OpenLDAP.org/its/ | ||
| + | |- | ||
| + | |邮件列表 || http://www.OpenLDAP.org/lists/ | ||
| + | |- | ||
| + | |手册页面 || http://www.OpenLDAP.org/software/man.cgi | ||
| + | |- | ||
| + | |软件页面 || http://www.OpenLDAP.org/software/ | ||
| + | |- | ||
| + | |支持页面 || http://www.OpenLDAP.org/support/ | ||
| + | |} | ||
| + | |||
| + | ''致谢'' | ||
| + | |||
| + | [http://www.openldap.org/project/ OpenLDAP项目]是一个由志愿者组成的团队。没有他们贡献的时间和精力本文是不可能的。 | ||
| + | |||
| + | 在OpenLDAP项目还要感谢美国[http://www.umich.edu/~dirsvcs/ldap/ldap.html 密西根大学的LDAP团队]对于LDAP软件和信息的建设,OpenLDAP软件是建立在它的基础上的。本文件是基于密歇根大学的以下文档而来的: [http://www.umich.edu/~dirsvcs/ldap/doc/guides/slapd/guide.pdf SLAPD和SLURPD管理员指南]。 | ||
| + | |||
| + | ''修正案'' | ||
| + | |||
| + | 对本文的建议改进和更正应使用[http://www.openldap.org/ OpenLDAP]问题跟踪系统( http://www.openldap.org/its/ )提交 。 | ||
| + | |||
| + | ''关于本文'' | ||
| + | |||
| + | 这份文件使用Ian Clatworthy开发的简单文件格式(SDF)文件系统( http://search.cpan.org/src/IANC/sdf-2.001/doc/catalog.html )。SDF工具可以从[http://cpan.org/ CPAN] ( http://search.cpan.org/search?query=SDF&mode=dist )得到。 | ||
| + | |||
| + | ==介绍OpenLDAP目录服务== | ||
| + | |||
| + | 本文描述如何编译,配置,以及操作OpenLDAP软件来提供目录服务. 这包括如何配置和运行独立的LDAP守护进程, slapd(8). 它对于新的和有经验的管理人员是一样的。 本节提供了一个基本的目录服务的介绍,尤其是slapd(8)所提供的目录服务的介绍. 这只是提供足够的信息,以便人们开始了解的LDAP , X.500和目录服务。 | ||
| + | |||
| + | ===什么是目录服务?=== | ||
| + | |||
| + | 目录是一个专门的数据库,专门用于搜索和浏览,另外也支持基本的查询和更新功能。 | ||
| + | |||
| + | 注意: 目录被一些人视为仅仅是一个优化了读取操作的数据库。这一定义,往最好了说,是过于简单化了。 | ||
| + | |||
| + | 目录往往包含描述性的,基于属性的信息和支持先进的过滤功能. 目录一般不支持被设计用于处理大批量复杂更新的数据库管理系统的复杂交易或回滚计划. 目录的更新通常是简单的全有或全无的变更,如果变更被允许的话。目录一般都调整为快速反应大批量查找或搜索操作. 它们可能有能力复制广泛的信息,以提高可用性和可靠性,同时降低响应时间. 当复制目录信息时,临时的复制品之间的不一致性可能可以接受,只要矛盾及时得到解决. | ||
| + | |||
| + | 有许多不同的方式提供一个目录服务. 不同的方法允许不同种类的信息存储在目录中,对于信息可以如何转发,查询和更新,以及如何保护未经授权的访问,等有不同的要求. 一些目录服务是本地的,提供服务给一个限制的范围内(例如,一台机器的finger服务). 其他服务是全球性的,提供服务给更广泛的范围内(例如,整个互联网) 。全球服务通常是分散的,也就是说,它们包含的数据是分散在许多机器,所有这些合作来提供目录服务. 通常情况下一个全球性的服务定义了一个统一的名字空间,提供同一视图的数据,无论您身在何处和数据本身有何关系。 | ||
| + | |||
| + | 一个网站目录,如开放式目录管理项目<http://dmoz.org>提供的 ,就是一个很好的目录服务例子. 这些服务把网页目录化,并专门设计用于支持浏览和搜索。 | ||
| + | |||
| + | 虽然有些人认为,因特网的域名系统( DNS )是一个例子,一个全球分布式目录服务,但是DNS是不能浏览或搜寻的. 它更准确的描述是一个全球型的分布查找服务. | ||
| + | |||
| + | ===什么是LDAP? === | ||
| + | |||
| + | LDAP表示轻型目录访问协议. 顾名思义,它是一个轻量级协议,用于访问目录服务,特别是基于X.500的目录服务. LDAP运行在TCP / IP或其他面向连接的传输服务. LDAP是一个IETF标准跟踪协议,在“轻量级目录访问协议( LDAP )技术规范路线图”RFC4510中被指定。 | ||
| + | |||
| + | 本节概述了从用户的角度来看LDAP的样子。 | ||
| + | |||
| + | 什么样的信息可以存储在目录? LDAP信息模型是基于条目的. 一个条目是一个属性的集合,有一个全球唯一的识别名( DN ). DN用于明白无误地标识条目. 每个条目的属性有一个类型和一个或多个值. 该类型通常是可记忆的字符串,如“ cn ”就是标识通用名称,或“电子邮件”就是电子邮件地址。 值的语法依赖于属性类型. 例如, 一个 cn 属性可以包含一个值 Babs Jensen. 一个 mail 属性可以包含值"babs@example.com". 一个 jpegPhoto 属性将包含一个JPEG (binary) 格式的照片. | ||
| + | |||
| + | 信息如何组织? 在LDAP, 目录条目都被排列在一个分层树形结构。传统上,这种结构反映了地域和/或组织界限. 代表国家的条目出现在树的顶端。它们下面是代表州和国家组织的条目. 再下面可能是代表组织单位,人,打印机,文档,或只是任何你你能想象到的东西. 图1.1所示的LDAP目录树中使用传统的命名。 | ||
| + | |||
| + | [http://www.openldap.org/doc/admin24/intro_tree.png http://www.openldap.org/doc/admin24/intro_tree.png] | ||
| + | |||
| + | 图 1.1: LDAP 目录树 (传统的命名) | ||
| + | |||
| + | 树也可以根据互联网域名组主。这种命名方式正越来越受欢迎,因为它允许使用DNS为目录服务定位 。图1.2所示的LDAP目录树中使用基于域的命名。 | ||
| + | |||
| + | [http://www.openldap.org/doc/admin24/intro_dctree.png http://www.openldap.org/doc/admin24/intro_dctree.png] | ||
| + | |||
| + | 图 1.2: LDAP 目录树(Internet命名) | ||
| + | |||
| + | 此外,可让您的LDAP控制在一个条目中哪个属性是必需的和允许的,通过使用一种特殊属性objectClass。objectClass属性的值确定条目必须遵守的架构规则。 | ||
| + | |||
| + | 信息是如何引用的的? 一个条目所引用的辨别名称,是构造于名字本身(称为相对辨别名称Relative Distinguished Name或RDN )再串连其祖先条目的名字。 例如, 在上面Internet命名例子里的条目 Barbara Jensen 有一个 RDN 为 uid=babs 和一个 DN 为 uid=babs,ou=People,dc=example,dc=com. 全 DN 格式在 RFC4514 中的 "LDAP: String Representation of Distinguished Names."有描述. | ||
| + | |||
| + | 如何访问信息? LDAP定义了查问和更新目录的操作. 提供的操作包括,从一个目录增加和删除一个条目,变更一个已存在的条目,以及变更一个条目的名字. 尽管,绝大部分时间, LDAP 是用于在目录中搜索信息. LDAP搜索操作允许目录的一些部分被搜索以寻找那些满足搜索过滤器规定的条件的条目. 可以请求每个和要求相匹配的条目的信息。 | ||
| + | |||
| + | 例如, 你可以在 dc=example,dc=com之下的整个目录树,搜索一个人,他的名字是 Barbara Jensen, 接收每个发现的条目的 email 地址. LDAP 让你很简单地完成这件事. 或者你可能想直接在st=California,c=US下搜索, organizations 为Acme 的所有条目的名字以及传真号码. LDAP 也能让你做到. 下一节对于你能用LDAP做什么和它如何帮助你做更详细的描述. | ||
| + | |||
| + | 如何从未授权的访问中保护信息? 一些目录服务不提供保护, 允许任何人查看信息. LDAP提供了给客户一个机制,向一个目录服务器验证或保护他的标识,提供了丰富的访问控制方法来保护服务器包含的信息. LDAP也支持数据安全 (完整性和保密性) 服务. | ||
| + | |||
| + | ===什么时候我应该使用LDAP?=== | ||
| + | |||
| + | 这是个非常好的问题. 通常,当你需要通过标准化的方法访问集中化管理和存储的数据时,你应该使用一个目录服务器. | ||
| + | |||
| + | 工业界一些常见(但不限于此)的例子如下: | ||
| + | |||
| + | :* 机器验证 | ||
| + | :* 用户验证 | ||
| + | :* 用户/系统 组 | ||
| + | :* 地址簿 | ||
| + | :* 组织机构表 | ||
| + | :* 资产跟踪 | ||
| + | :* 电话信息存储 | ||
| + | :* 用户资源管理 | ||
| + | :* E-mail地址查找 | ||
| + | :* 应用配置存储 | ||
| + | :* PBX配置存储 | ||
| + | :* 其他..... | ||
| + | |||
| + | 虽然有各种基于标准的分布式规划文件, 但是你总是可以建立自己的规划规范. | ||
| + | |||
| + | 你总是可以有新的办法来使用目录和应用LDAP原理来解决特定的问题, 所以这个问题不存在一个简单的答案. | ||
| + | |||
| + | 如果有任何疑问, 加入常见的 LDAP 论坛来参加非商业性的讨论和获得关于LDAP的信息: http://www.umich.edu/~dirsvcs/ldap/mailinglist.html | ||
| + | |||
| + | ===什么时候我不应使用LDAP?=== | ||
| + | |||
| + | 当你开始发现自己用目录来做你需要做的事情的时候很别扭, 就可能需要重新设计了(译者:这不等于没说吗?). 或者你只是需要一个应用来使用和操作你的数据(关于 LDAP vs RDBMS, 参见 LDAP vs RDBMS 节). | ||
| + | |||
| + | 当LDAP对某项工作很合适的时候,很明显就能看出来(译者:还是白说啊)。 | ||
| + | |||
| + | ===LDAP是如何工作的?=== | ||
| + | |||
| + | LDAP采用客户-服务器模式. 包含在一个或多个LDAP服务器中的数据组成了目录信息树(DIT). 客户端连接到服务器然后问一个问题. 服务器返回一个应答和/或一个指针告诉客户端去哪里获得更多的信息 (通常是另一台 LDAP 服务器). 客户端连接哪台LDAP服务器不重要, 目录的视图看起来都一样; 一个提交到某台LDAP服务器的名字在另一台LDAP服务器上也将指向相同的条目. 这是全球目录服务的一个重要功能. | ||
| + | |||
| + | ===关于X.500?=== | ||
| + | |||
| + | 技术上来讲, LDAP是一个针对X.500目录服务(OSI目录服务)的目录访问协议. 起初, LDAP客户端通过网关访问 X.500 目录服务. 客户端和网关之间跑的是LDAP,而网关和X.500服务之间跑的是 X.500 的 目录访问协议 (DAP) . DAP是一个重量级的协议,它操作完整的OSI协议栈并且需要大量的计算资源. LDAP设计成通过TCP/IP操作并以非常少的开销来提供DAP的大部分功能. | ||
| + | |||
| + | 虽然 LDAP 仍被用于通过网关访问 X.500 目录服务, LDAP 现在更常见的是直接在X.500服务器上实现. | ||
| + | |||
| + | 标准的 LDAP 守护进程, 或曰 slapd(8), 可以被视为一个轻量级的 X.500 目录服务. 也就是说, 它既不由 X.500's DAP 实现,也不支持完整的 X.500 模型. | ||
| + | |||
| + | 如果你以及功能运行了一个 X.500 DAP 服务并且你想继续这么干, 可能你不用读这本指南了. 这份指南全部是关于通过 slapd(8)运行 LDAP , 而不是运行 X.500 DAP. 如果你没有运行 X.500 DAP, 希望停止运行 X.500 DAP, 或最近没有打算运行 X.500 DAP, 请继续. | ||
| + | |||
| + | 从一个 LDAP 目录服务器复制数据到一个 X.500 DAP DSA 是有可能的. 这需要一个 LDAP/DAP 网关. OpenLDAP软件不包含这样一个网关. | ||
| + | |||
| + | ===LDAPv2和LDAPv3之间有何不同?=== | ||
| + | |||
| + | LDAPv3在20实际90年代末期开发用来替代LDAPv2. LDAPv3 为LDAP增加了以下功能: | ||
| + | |||
| + | :* 使用SASL实现强验证和数据安全服务 | ||
| + | :* 使用TLS (SSL)实现证书验证和数据安全服务 | ||
| + | :* 使用Unicode实现国际化 | ||
| + | :* 转发和配置 | ||
| + | :* 规划发现 | ||
| + | :* 扩展性 (控制, 扩展操作, 以及更多) | ||
| + | |||
| + | LDAPv2 过时了 (RFC3494). 大部分所谓LDAPv2实现(including slapd(8))已经不符合LDAPv2技术规范了, 那些声称支持LDAPv2的实现之间的互操作性是有限的. 由于LDAPv2和LDAPv3显著的差异, 同时部署LDAPv2和LDAPv3是很成问题的. 应该避免使用LDAPv2. LDAPv2缺省是被禁用的. | ||
| + | |||
| + | ===LDAP vs RDBMS=== | ||
| + | |||
| + | 这个问题被提到很多次,以不同的形式. 最常见的是: 为什么OpenLDAP不放弃 Berkeley DB 而使用一个关系型数据库管理系统(RDBMS)替代它? 通常, 我们可以预期商业级RDBMS的复杂算法将使 OpenLDAP 更快或者反正是更好, 同时允许其他应用程序分享其数据. | ||
| + | |||
| + | 简单的答案是,使用嵌入式数据库和定制的索引系统允许OpenLDAP提供更高的性能和可扩展性而又不减少可靠性. OpenLDAP使用Berkeley DB并行/事务数据库软件. 业界领先的商业目录软件也使用同样的软件. | ||
| + | |||
| + | 现在来详细回答一下. 任何时候我们总是面对 RDBMSes vs. directories的选择. 很难选择,并且不存在简单的答案. | ||
| + | |||
| + | 给目录一个关系数据库管理系统的后端来解决所有问题,这个想法无疑是很诱人的. 无论如何, 它是一头猪(译者:呃,老外骂人了). 这是因为数据模型是非常不同的. 用关系型数据库去表现目录数据,将需要把数据分割到多个表里面. | ||
| + | |||
| + | 考虑一下关于 person 这个 objectclass. 它的定义需要属性类型 objectclass, sn 和 cn,并且允许属性类型 userPassword, telephoneNumber, seeAlso 以及 description. 所有这些属性都是多值的, 所以一个常规的需求就会把每个属性类型放大一个单独的表里面. | ||
| + | |||
| + | 现在你不得不决定这些表的适当的键. 主键可能是一个DN的组合, 但是这在绝大多数数据库实现中是非常低效的. | ||
| + | |||
| + | 现在的大问题是根据一个条目请求去不同的磁盘区域访问数据. 在某些应用里面这个还可以做到,但是在很多应用里面性能就很困难. | ||
| + | |||
| + | 唯一可以放到主表条目里面的属性类型是那些强制性的和单值的. 你也可以增加可选性的单值属性并把他们设为NULL或其他什么东西. | ||
| + | |||
| + | 但是请等一下, 这个条目有多个 objectclasses并且他们组织成一个继承的层次. 一个 objectclass organizationalPerson 的条目现在有从 person 来的属性加上一些其他的以及一些原有的可选的属性类型现在变成强制性的了. | ||
| + | |||
| + | 怎么办? 我们应该用不同的表放不同的objectclasses吗? 这样 person 将有一个条目在 person 表, 另一个在 organizationalPerson表, 以此类推. 或我们应该不管 person 而把每样东西放在第二个表? | ||
| + | |||
| + | 但是对于类似(cn=*) 这样的过滤器,cn是一个在很多很多objectclasses里出现的属性类型,我们怎么办? 我们应该为匹配那个过滤器搜索所有可能的表吗? 不是很有吸引力. | ||
| + | |||
| + | 一旦达到这种程度, 三种办法浮现在脑海中。 一个是做全面正常化,以使每个属性类型,不管如何,都有自己单独的表。简单的方法DN作为主键的一部分是非常浪费的, 并且调用的是那个条目的唯一性的数字id而不是键,并且需要一个表来负责映射DN到id。这个方法, 无论如何, 当从一个或多个条目中请求很多属性类型的时候是非常低效的. 这样一个数据库, 尽管繁琐, 也可能由SQL应用程序管理. | ||
| + | |||
| + | 第二个办法是把整个DN作为一个blob类型字段存在表里由所有条目共享,不管objectclass,并且额外的表作为第一个表的索引. 索引表不是数据库索引, 而是完全由LDAP服务端实现来管理. 无论如何, 无法利用SQL数据库了. 因此,一个完全成熟的数据库系统很少或根本没有优势. 全功能的通用数据库是不需要的. 更好的办法是使用一些轻型快速的, 如 Berkeley DB. | ||
| + | |||
| + | 从一种完全不同的方式来看这件事,就是放弃任何实现目录数据模型的希望。在这种情况下, LDAP被用作一个对数据的访问协议,这些数据仅提供目录数据模型层面的数据. 例如,它可能是只读,或允许更新,适用限制,如单值属性类型允许多个值。或无法添加新的objectclasses到现有的条目或删除其中之一。限制范围的跨度从允许的限制(可能在其他地方造成的访问控制结果),到直接侵犯数据模型。无论如何,它是一个可行的办法,对之前就存在的用于其它应用程序的数据提供LDAP操作. 但是从概念上讲,我们并不真的拥有一个"目录". | ||
| + | |||
| + | 现有的商业LDAP服务器采用关系数据库实现的,都是从第一种或第三种方法。我不知道任何使用关系数据库的实现如何低效地执行BDB做起来很高效的事情。 对那些对"第三种"方法感兴趣的人来说 (把现有的数据的数据库管理系统作为的LDAP树,比起典型的LDAP模式有一定的局限性,但有可能在LDAP和SQL应用之间实现互操作性): | ||
| + | |||
| + | OpenLDAP包含了 back-sql - 这个后端使得它(第三种方法)成为可能. 它使用 ODBC + 扩展来把LDAP查询翻译成你的RDBMS规划的SQL查询, 提供不同的级别的操作 - 从只读到全访问,取决于你使用的 RDBMS , 和你的规划. | ||
| + | |||
| + | 更多关于概念和限制的信息, 见 slapd-sql(5) 手册页, 或 Backends 一节. 在 back-sql/rdbms_depend/* 子目录也有很多关于RDBMS的例子. | ||
| + | |||
| + | ===什么是slapd以及它能干什么?=== | ||
| + | |||
| + | slapd(8) 是一个 LDAP 目录服务期,可以运行在各种不同的平台之上. 你可使用它提供一个你自己的目录服务. 你的目录可能包含非常多期望放进去的东西. 你可以把它连接到全球 LDAP 目录服务中, 或完全自己运行一个目录服务. 一些 slapd's 更有意思的功能和能力包括: | ||
| + | |||
| + | LDAPv3: slapd实现了轻量级目录访问协议的版本3. slapd支持 LDAP 运行于 IPv4 和 IPv6 以及 Unix IPC. | ||
| + | |||
| + | 简单验证和安全层: slapd通过使用SASL支持强验证和数据安全(完整性和保密性) 服务. slapd的SASL实现利用了 Cyrus SASL 软件,它支持不少机制,包括 DIGEST-MD5, EXTERNAL, 和 GSSAPI. | ||
| + | |||
| + | 传输层安全: slapd通过使用TLS的(或SSL )支持基于证书的身份验证和数据安全(完整性和保密性)服务。slapd的TLS实现可以利用OpenSSL或GnuTLS软件。 | ||
| + | |||
| + | 拓扑控制: slapd可以被配置为根据网络的拓扑结构信息限制访问的套接字层。此功能利用了TCP包装。 | ||
| + | |||
| + | 访问控制: slapd提供了丰富和强大的访问控制设施,使您可以控制对你的数据库的信息的获取 。您可以基于LDAP授权信息, IP地址,域名和其他标准控制对条目的访问。slapd支持静态和动态的访问控制信息。slapd provides a rich and powerful access control facility, | ||
| + | |||
| + | 国际化: slapd支持Unicode和语言标签。 | ||
| + | |||
| + | 可选的数据库后端: slapd配备了各种不同的数据库后端您可以从中选择。它们包括BDB,一个高性能的交易数据库后端;HDB,一个分级的高性能的交易后端;SHELL,一个后端接口通向任意 shell脚本;和PASSWD,一个简单的后端接口,到passwd ( 5 )文件。BDB和HDB后端利用了Oracle Berkeley DB。 | ||
| + | |||
| + | 多数据库实例: slapd可以配置为在同一时间服务多个数据库。这意味着,一个单一的slapd服务器能够使用相同或不同的数据库后端,响应许多逻辑上不同的LDAP树的请求。 | ||
| + | |||
| + | 通用模块API :如果您需要更加个性化, slapd让你轻松地写自己的模块。slapd包括两个不同的部分:处理和LDAP客户沟通协议的前端;和处理特定任务,如数据库操作的模块。因为这两个部分之间通过一个明确界定的C API通讯 ,你可以用多种方式写自己的定制模块扩展slapd。此外,提供了一些可编程数据库模块。这些允许你使用流行的编程语言( Perl,shell和SQL )暴露外部数据源给slapd 。 | ||
| + | |||
| + | 线程: slapd是线程高性能的。一个单一的多线程slapd进程使用线程池处理所有传入的请求。这减少了系统开销,同时提供所需的高性能。 | ||
| + | |||
| + | 复制: slapd可以被配置为维护目录信息的影子复制。这个单主/多从复制规划,对于安装单一的slapd而不提供必要的可用性和可靠性的高容量环境,是至关重要的。对于不能接受单点故障的要求极高的环境,也可以用多主复制。 slapd包含了对LDAP基于同步的复制的支持。 | ||
| + | |||
| + | 代理缓存: slapd可以被配置为一个缓存的LDAP代理服务。 | ||
| + | |||
| + | 配置: slapd是高度可配置的,通过一个单一的配置文件你可以改变一切,任何你想改变的东西。配置选项有合理的默认值,使您的工作更加容易。配置也可以使用LDAP本身动态的执行,这极大地改善了可管理性。 | ||
| + | |||
| + | ==快速开始指南== | ||
| + | |||
| + | 以下是一个OpenLDAP2.4的快速开始指南, 包含独立的LDAP守护进程, slapd(8). | ||
| + | |||
| + | 这表示带你走过安装和配置OpenLDAP软件所需要的基本步骤. 应该结合其它文档一起来看,包括本文的其他章节,手册页面,以及其随同软件提供的材料(例如INSTALL文档)或OpenLDAP网站(http://www.OpenLDAP.org),特别是OpenLDAP的常见问题解答(http://www.OpenLDAP.org/faq/?file=2)。 | ||
| + | |||
| + | 如果你打算严肃使用OpenLDAP软件, 你应该在尝试安装软件之前阅读本文的全文. | ||
| + | |||
| + | 注意: 这个快速开始指南没有使用强验证或任何保密服务. 这些服务在本OpenLDAP管理员指南的其它章节里有所描述. | ||
| + | |||
| + | :1. 获得软件 | ||
| + | ::你可以跟着OpenLDAP软件下载页面 (http://www.openldap.org/software/download/) 的提示获得一份软件拷贝. 建议新用户使用最新版本. | ||
| + | |||
| + | :2. 解包分发版 | ||
| + | ::给源码选择一个目录, 进入到那个目录, 使用以下命令解包分发版: | ||
| + | <source lang="bash"> | ||
| + | gunzip -c openldap-VERSION.tgz | tar xvfB - | ||
| + | </source> | ||
| + | ::然后进入分发版的目录: | ||
| + | <source lang="bash"> | ||
| + | cd openldap-VERSION | ||
| + | </source> | ||
| + | ::你要把VERSION换成相应的版本名. | ||
| + | |||
| + | :3. 阅读文档 | ||
| + | ::你现在应该阅读分发版所提供的COPYRIGHT, LICENSE, README 和 INSTALL 文档. COPYRIGHT 和 LICENSE 提供的信息是关于可接受的使用,拷贝方式和OpenLDAP软件的有限保证. | ||
| + | |||
| + | ::你也应该阅读本文的其他章节. 特别是, 本文的编译和安装OpenLDAP软件章节提供了依赖的软件的详细信息和安装过程. | ||
| + | |||
| + | :4. 运行configure | ||
| + | ::你将需要运行提供的configure脚本来配置分发版使它能在你的系统上进行编译. configure脚本接受很多命令行选项以打开或关闭可选的软件功能. 通常缺省就差不多了, 但是你可以改变它们. 要获得configure可接受的选项的完整列表, 使用 --help 选项: | ||
| + | <source lang="bash"> | ||
| + | ./configure --help | ||
| + | </source> | ||
| + | ::无论如何, 是你在使用这个指南, 我们假定你足够勇敢,就让configure决定什么是最好的: | ||
| + | <source lang="bash"> | ||
| + | ./configure | ||
| + | </source> | ||
| + | ::假定configure不喜欢你的系统, 你可以继续编译软件. 如果configure抱怨, 那么, 你可能需要去看看软件常见问题解答的安装一节 (http://www.openldap.org/faq/?file=8) 和/或仔细阅读本文的编译和安装OpenLDAP软件一章. | ||
| + | |||
| + | :5. Build软件. | ||
| + | ::下一步是编译软件. 这一步分为两部分, 首先我们构建依赖,然后我们编译软件: | ||
| + | <source lang="bash"> | ||
| + | make depend | ||
| + | make | ||
| + | </source> | ||
| + | ::两个 makes 都应该不出错地完成. | ||
| + | |||
| + | :6. 测试build. | ||
| + | ::为了确保正确的编译, 你应该运行测试套件(只要花几分钟): | ||
| + | <source lang="bash"> | ||
| + | make test | ||
| + | </source> | ||
| + | ::应用你的配置的测试将运行并应该通过. 一些测试, 例如复制测试, 可以忽略. | ||
| + | |||
| + | :7. 安装软件. | ||
| + | ::你现在准备安装软件; 这通常需要超级用户权限: | ||
| + | <source lang="bash"> | ||
| + | su root -c 'make install' | ||
| + | </source> | ||
| + | ::现在每样东西应该都被安装在 /usr/local 目录下(或任何configure指定的安装前缀). | ||
| + | |||
| + | :8. 编辑配置文件. | ||
| + | ::使用你偏爱的编辑器编辑附带的slapd.conf(5)例子(通常安装在 /usr/local/etc/openldap/slapd.conf) 来包含一个如下格式的 BDB 数据库定义: | ||
| + | <source lang="ini"> | ||
| + | database bdb | ||
| + | suffix "dc=<MY-DOMAIN>,dc=<COM>" | ||
| + | rootdn "cn=Manager,dc=<MY-DOMAIN>,dc=<COM>" | ||
| + | rootpw secret | ||
| + | directory /usr/local/var/openldap-data | ||
| + | </source> | ||
| + | ::确保以你的域名的适当部分替换<MY-DOMAIN>和<COM> . 例如, 对于 example.com, 使用: | ||
| + | <source lang="ini"> | ||
| + | database bdb | ||
| + | suffix "dc=example,dc=com" | ||
| + | rootdn "cn=Manager,dc=example,dc=com" | ||
| + | rootpw secret | ||
| + | directory /usr/local/var/openldap-data | ||
| + | </source> | ||
| + | ::如果你的域包含额外的部分, 例如 eng.uni.edu.eu, 使用: | ||
| + | <source lang="ini"> | ||
| + | database bdb | ||
| + | suffix "dc=eng,dc=uni,dc=edu,dc=eu" | ||
| + | rootdn "cn=Manager,dc=eng,dc=uni,dc=edu,dc=eu" | ||
| + | rootpw secret | ||
| + | directory /usr/local/var/openldap-data | ||
| + | </source> | ||
| + | ::关于配置slapd(8)的细节,可在slapd.conf(5) 手册页,以及本文的 slapd 配置文件 一章找到. 注意启动slapd(8)之前那些定义的目录必须实际存在. | ||
| + | |||
| + | :9. 启动SLAPD. | ||
| + | ::现在你准备启动独立的LDAP守护进程, slapd(8), 运行这个命令: | ||
| + | <source lang="bash"> | ||
| + | su root -c /usr/local/libexec/slapd | ||
| + | </source> | ||
| + | ::为了检查服务器是否运行以及是否被正确地配置好, 你可以使用ldapsearch(1)针对它运行一个搜索. 缺省的, ldapsearch被安装在 /usr/local/bin/ldapsearch: | ||
| + | <source lang="bash"> | ||
| + | ldapsearch -x -b '' -s base '(objectclass=*)' namingContexts | ||
| + | </source> | ||
| + | ::注意在命令参数周围使用单引号来避免shell被特殊字符中断. 它应该返回: | ||
| + | <source lang="bash"> | ||
| + | dn: | ||
| + | namingContexts: dc=example,dc=com | ||
| + | </source> | ||
| + | ::关于运行slapd(8)的细节可以在slapd(8)手册页以及本文的 运行slapd 一章找到. | ||
| + | |||
| + | :10. 添加初始条目到目录中去. | ||
| + | ::你可以使用ldapadd(1)添加条目到你的LDAP目录. ldapadd期待的输入是LDIF格式. 我们将分两步走: | ||
| + | :# 建立LDIF文件 | ||
| + | :# 运行ldapadd | ||
| + | |||
| + | :使用你偏爱的编辑器新建一个LDIF文件,包含如下内容: | ||
| + | <source lang="text"> | ||
| + | dn: dc=<MY-DOMAIN>,dc=<COM> | ||
| + | objectclass: dcObject | ||
| + | objectclass: organization | ||
| + | o: <MY ORGANIZATION> | ||
| + | dc: <MY-DOMAIN> | ||
| + | |||
| + | dn: cn=Manager,dc=<MY-DOMAIN>,dc=<COM> | ||
| + | objectclass: organizationalRole | ||
| + | cn: Manager | ||
| + | </source> | ||
| + | ::确保使用你的域名的适当部分替换<MY-DOMAIN>和<COM>. <MY ORGANIZATION>应该被你的机构名称替换掉. 当你剪切粘贴时, 确定本例中的每一行的前面和后面都没有空格. | ||
| + | <source lang="text"> | ||
| + | dn: dc=example,dc=com | ||
| + | objectclass: dcObject | ||
| + | objectclass: organization | ||
| + | o: Example Company | ||
| + | dc: example | ||
| + | |||
| + | dn: cn=Manager,dc=example,dc=com | ||
| + | objectclass: organizationalRole | ||
| + | cn: Manager | ||
| + | </source> | ||
| + | ::现在, 你可以运行ldapadd(1)来添加这些条目到你的目录. | ||
| + | <source lang="bash"> | ||
| + | ldapadd -x -D "cn=Manager,dc=<MY-DOMAIN>,dc=<COM>" -W -f example.ldif | ||
| + | </source> | ||
| + | ::确保用你的域名的适当部分替换<MY-DOMAIN>和<COM>. 你将收到提示输入密码,也就是在slapd.conf中定义的"secret". 例如, 对于 example.com, 使用: | ||
| + | <source lang="bash"> | ||
| + | ldapadd -x -D "cn=Manager,dc=example,dc=com" -W -f example.ldif | ||
| + | </source> | ||
| + | ::这里example.ldif就是你上面新建的文件. | ||
| + | |||
| + | ::另外关于建立目录的信息可以在本文的 数据库建立和维护工具 一章找到. | ||
| + | |||
| + | :11. 看它是否起作用. | ||
| + | ::现在我们准备检验目录中添加的条目. 你可使用任何LDAP客户端来做这件事, 但我们的例子使用ldapsearch(1)工具. 记住把 dc=example,dc=com 替换成你的网站的正确的值: | ||
| + | <source lang="bash"> | ||
| + | ldapsearch -x -b 'dc=example,dc=com' '(objectclass=*)' | ||
| + | </source> | ||
| + | ::本命令将搜索和接收这个数据库中的每一个条目. | ||
| + | |||
| + | 现在你准备使用ldapadd(1)或其它LDAP客户端添加更多的条目, 试验更多的配置选项, 后端安排, 等等. | ||
| + | |||
| + | 注意缺省的情况下, slapd(8)数据库赋予阅读权限给每个人,除了超级用户(即配置文件中的rootdn参数). 强烈建议你建立控制来限制授权用户的操作. 操作权限控制在 访问控制 章讨论. 也鼓励你阅读安全事项,使用SASL和使用TLS章节. | ||
| + | |||
| + | 接下来的章节提供更多编译,安装和运行slapd(8)的详细信息. | ||
| + | |||
| + | ==大图片-配置选择== | ||
| + | |||
| + | 本节概述了各种LDAP目录配置,以及如何使您的独立的LDAP守护进程slapd ( 8 )适合世界其他国家。 | ||
| + | |||
| + | ===本地目录服务=== | ||
| + | |||
| + | 在这种配置中,您运行slapd ( 8 )实例,只为您的本地网域提供目录服务。它不以任何方式与其他目录服务器交互。这种配置如图3.1. | ||
| + | |||
| + | [http://www.openldap.org/doc/admin24/config_local.png http://www.openldap.org/doc/admin24/config_local.png] | ||
| + | |||
| + | 图 3.1: 本地服务配置. | ||
| + | |||
| + | 如果您刚刚起步(快速启动指南的目的之一就是为了你这种人),或者如果你想提供本地服务且对连接到世界其他地区不感兴趣,请使用此配置。如果以后你想的话,这也很容易升级到另一个配置。 | ||
| + | |||
| + | ===带转发的本地服务=== | ||
| + | |||
| + | 在这种配置中,您运行slapd ( 8 )实例,为您的本地网域提供目录服务,并配置它返回转发到其他能够处理请求的服务器。您可以自己运行此服务(或多个服务)或使用别人提供给您的服务。这种配置如图3.2. | ||
| + | |||
| + | [http://www.openldap.org/doc/admin24/config_ref.png http://www.openldap.org/doc/admin24/config_ref.png] | ||
| + | |||
| + | 图 3.2: 带转发的本地服务 | ||
| + | |||
| + | 如果你想提供本地服务,并参与全球目录,或者您想代表负责下属条目到另一台服务器,使用此配置。 | ||
| + | |||
| + | ===可复制的目录服务=== | ||
| + | |||
| + | slapd ( 8 )包括了对LDAP基于同步的复制的支持, 即所谓syncrepl ,可用于在多个目录服务器上维持目录信息的影子复制。在其最基本的配置,主服务器是一个syncrepl供应商,而一个或多个从服务器(或影子服务器)是syncrepl消费者。一个主从配置的例子如图3.3. 多主机的配置,也支持。 | ||
| + | |||
| + | [http://www.openldap.org/doc/admin24/config_repl.png http://www.openldap.org/doc/admin24/config_repl.png] | ||
| + | |||
| + | 图 3.3: 可复制的目录服务 | ||
| + | |||
| + | 此配置可用于头两个配置的任何一个情况下,例如一个单一的slapd ( 8 )没有提供所需的可靠性和可用性。 | ||
| + | |||
| + | ===分布式本地目录服务=== | ||
| + | |||
| + | 在这种配置中,当地的服务被分割成较小的服务,每个都是可复制的,和上下级粘在一起转发。 | ||
| + | |||
| + | ==编译和安装OpenLDAP软件== | ||
| + | |||
| + | 这一章详细说明如何编译和安装包含了slapd ( 8 ) ,独立的LDAP守护进程的OpenLDAP软件包。编译和安装OpenLDAP软件需要几个步骤:安装依赖的软件,配置OpenLDAP软件本身,编译,并最终安装。以下各节详细描述了此过程中。 | ||
| + | |||
| + | ===获得和解包软件=== | ||
| + | |||
| + | 您可以从该项目的下载页面上http://www.openldap.org/software/download/或直接从该项目的FTP服务在ftp://ftp.openldap.org/pub/OpenLDAP/获取OpenLDAP软件 。 | ||
| + | |||
| + | 该项目提供两个系列的包作为一般用途。该项目发布版本提供新的特性和错误修正。虽然该项目采取措施,以改善这些版本的稳定性,但是经常会版本发布之后才发现问题。稳定版本是最新的经过一般性的使用已经显示出稳定的版本。 | ||
| + | |||
| + | OpenLDAP软件的用户可以选择最适当的一系列安装,这取决于他们对于最新功能与稳定表现的期望。 | ||
| + | |||
| + | OpenLDAP软件下载后,你需要从压缩存档文件提取发布版并更改您的工作目录到发布版的根目录: | ||
| + | <source lang="bash"> | ||
| + | gunzip -c openldap-VERSION.tgz | tar xf - | ||
| + | cd openldap-VERSION | ||
| + | </source> | ||
| + | 你需要把 VERSION 换成发布版的实际版本号. | ||
| + | |||
| + | 您现在应该阅读版权,许可证,自述文件和发布版提供的安装文件规定。版权和许可提供对OpenLDAP软件的可接受的使用,复制,和限制的保证。自述文件和安装文件提供依赖的软件和安装过程的详细资料。 | ||
| + | |||
| + | ===依赖的软件=== | ||
| + | |||
| + | OpenLDAP软件依靠一些第三方分发的软件包。根据您打算使用的不同的功能,您可能必须下载并安装一些额外的软件包。本节详述通常需要的您可能需要安装的第三方软件的软件包。然而,一个最新的依赖软件信息,应在自述文件中获得。请注意,其中一些第三方软件包可能依赖于额外的软件包。每个软件包提供了它自己的安装说明。 | ||
| + | |||
| + | ====传输层安全==== | ||
| + | |||
| + | OpenLDAP客户端和服务器需要安装OpenSSL或GnuTLS的TLS库来提供TLS,传输层安全服务。虽然一些操作系统可能提供这些库的一部分,作为基本系统或一个可选的软件组件, OpenSSL和GnuTLS往往需要单独安装。 | ||
| + | |||
| + | OpenSSL可从 http://www.openssl.org/ 获得. GnuTLS 可从 http://www.gnu.org/software/gnutls/ 获得. | ||
| + | |||
| + | OpenLDAP 软件将不是完全兼容 LDAPv3,除非 OpenLDAP 的配置检测到一个可用的 TLS 库. | ||
| + | |||
| + | ====简单验证和安全层==== | ||
| + | |||
| + | OpenLDAP客户端和服务器需要安装 Cyrus SASL 库提供简单身份认证和安全层服务。虽然一些操作系统可能会提供这个库,作为基本系统的一部分或作为一个可选的软件组件,Cyrus SASL 往往需要单独安装。 | ||
| + | |||
| + | Cyrus SASL 可从 http://asg.web.cmu.edu/sasl/sasl-library.html 获得. Cyrus SASL 将使用 OpenSSL 和 Kerberos/GSSAPI 库,如果预先安装了的话. | ||
| + | |||
| + | OpenLDAP软件将不完全兼容 LDAPv3,除非 OpenLDAP 的配置检测到一个可用的 Cyrus SASL 安装. | ||
| + | |||
| + | ====Kerberos验证服务==== | ||
| + | |||
| + | OpenLDAP客户端和服务器支持Kerberos身份验证服务。特别是, OpenLDAP支持 Kerberos V GSS-API SASL 认证机制,称为GSSAPI机制。此功能要求,除了Cyrus SASL 库之外,还要有 Heimdal 或 MIT Kerberos V 库。 | ||
| + | |||
| + | Heimdal Kerberos 可从 http://www.pdc.kth.se/heimdal/ 获得. MIT Kerberos 可从 http://web.mit.edu/kerberos/www/ 获得. | ||
| + | |||
| + | 强烈推荐使用强验证服务, 例如 Kerberos 提供的那些. | ||
| + | |||
| + | ====数据库软件==== | ||
| + | |||
| + | OpenLDAP的slapd ( 8 )的BDB和HDB主要数据库后端需要甲骨文公司的Berkeley DB。如果在设定的时间没有可用的,您将无法与这些主要的数据库后端编译slapd ( 8 )。 | ||
| + | |||
| + | 您的操作系统可能提供一个支持版本的Berkeley DB作为基础系统或作为一个可选的软件组件。如果不是这样,您将不得不自己去获取并安装它。 | ||
| + | |||
| + | Berkeley DB 可从 Oracle 公司的 Berkeley DB 下载页 http://www.oracle.com/technology/software/products/berkeley-db/index.html 获得. | ||
| + | |||
| + | 有很多可用的版本. 通常, 推荐最近的版本 (包含发布的补丁) . 如果你想使用BDB或HDB数据库后端,这个包是必需的. | ||
| + | |||
| + | 注意: 请看推荐的 OpenLDAP 软件依赖版本 一节获得更多信息. | ||
| + | |||
| + | ====线程==== | ||
| + | |||
| + | OpenLDAP设计成充分利用线程。 OpenLDAP支持POSIX pthreads,Mach CThreads ,以及其他一些品种。如果不能找到一个合适的线程子系统,configure会抱怨。如果发生这种情况,请咨询OpenLDAP常见问题 http://www.openldap.org/faq/ 中的 软件|安装|平台 提示部分 。 | ||
| + | |||
| + | ====TCP包装==== | ||
| + | |||
| + | slapd(8) 支持 TCP 包装 (IP 级访问控制过滤), 如果预先安装了的话. 建议为包含非公开信息的服务器使用 TCP 包装或其他 IP级的访问过滤 (例如那些IP级防火墙所提供的). | ||
| + | |||
| + | ===运行configure=== | ||
| + | |||
| + | 现在,您或许应该运行configure脚本的 --help 选项。这将给你一个选项列表,编译OpenLDAP时您可以变更这些选项 。使用此方法可以启用或禁用OpenLDAP的许多功能。 | ||
| + | <source lang="bash"> | ||
| + | ./configure --help | ||
| + | </source> | ||
| + | configure脚本还将研究各种环境变量的某些设置。这些环境变量包括: | ||
| + | |||
| + | '''表 4.1: 环境标量''' | ||
| + | {|border="1" cellspacing="0" | ||
| + | !变量 !! 描述 | ||
| + | |- | ||
| + | |CC || 指定替代的 C 编译器 | ||
| + | |- | ||
| + | |CFLAGS || 指定额外的编译器 flags | ||
| + | |- | ||
| + | |CPPFLAGS || 指定 C 预编译器 flags | ||
| + | |- | ||
| + | |LDFLAGS || 指定 linker flags | ||
| + | |- | ||
| + | |LIBS || 指定额外的库 | ||
| + | |} | ||
| + | 现在以任何期望的配置选项或环境变量运行configure脚本. | ||
| + | <source lang="bash"> | ||
| + | [[env] settings] ./configure [options] | ||
| + | </source> | ||
| + | 作为一个例子,假设我们要安装OpenLDAP,后端是BDB并支持TCP封装。默认情况下,BDB是启用的而TCP封装并非如此。所以,我们只需要指定 --with-wrappers, 来包含对TCP封装的支持: | ||
| + | <source lang="bash"> | ||
| + | ./configure --with-wrappers | ||
| + | </source> | ||
| + | 无论如何,这无法定位没有安装到系统目录的依赖的软件. 例如, 如果 TCP Wrappers 头文件和库文件分别被安装在 /usr/local/include 和 /usr/local/lib, configure 脚本应该如下调用: | ||
| + | <source lang="bash"> | ||
| + | env CPPFLAGS="-I/usr/local/include" LDFLAGS="-L/usr/local/lib" \ | ||
| + | ./configure --with-wrappers | ||
| + | </source> | ||
| + | 注意: 一些 shells, 例如那些衍生自Bourne sh(1)的 shell, 不需要使用 env(1) 命令. 在某些情况下, 环境变量不得不使用替代的语法来指定. | ||
| + | |||
| + | configure脚本通常将自动检测适当的设定. 如果你对此阶段有任何问题, 咨询任何平台特定的提示并检查你的configure选项, 如果有的话. | ||
| + | |||
| + | ===编译软件=== | ||
| + | |||
| + | 一旦你运行了 configure 脚本,输出的最后一行应该是: | ||
| + | <source lang="bash"> | ||
| + | Please "make depend" to build dependencies | ||
| + | </source> | ||
| + | 如果最后一行输出不符, configure失败了, 你需要阅读它的输出来决定什么地方出错了. 你不应继续下去,直到configure成功的完成. | ||
| + | |||
| + | 编译依赖, 运行: | ||
| + | <source lang="bash"> | ||
| + | make depend | ||
| + | </source> | ||
| + | 现在编译软件, 这一步将确实地编译OpenLDAP. | ||
| + | <source lang="bash"> | ||
| + | make | ||
| + | </source> | ||
| + | 你应该仔细检查这个命令的输出信息以确认每件东西正确地被编译了. 注意这个命令同时编译了 LDAP 库文件和相关的客户端以及 slapd(8). | ||
| + | |||
| + | ===测试软件=== | ||
| + | |||
| + | 一旦软件被正确地配置和成功地编译了, 你应该运行测试套件来检查这个版本. | ||
| + | <source lang="bash"> | ||
| + | make test | ||
| + | </source> | ||
| + | 适用于您的配置地试验将运行,它们应该通过。一些测试,如复制测试,可以跳过,如果您的配置不支持的话。 | ||
| + | |||
| + | ===安装软件=== | ||
| + | |||
| + | 一旦你成功地测试了软件, 你开始准备安装它. 你将需要在运行configure时你指定的那些安装目录的写权限. 缺省OpenLDAP软件安装在/usr/local. 如果你用 --prefix configure 选项改变了设置 , 它将被安装在你提出的位置. | ||
| + | |||
| + | 典型的, 安装需要超级用户权限. 从OpenLDAP源码根目录, 键入: | ||
| + | <source lang="bash"> | ||
| + | su root -c 'make install' | ||
| + | </source> | ||
| + | 需要的时候输入适当的密码. | ||
| + | |||
| + | 你应该仔细检查此命令的输出以确保每件东西正确地安装了. 缺省你将在 /usr/local/etc/openldap 发现slapd(8)的配置文件. 更多信息见 配置 slapd 一章. | ||
| + | |||
| + | ==配置slapd== | ||
| + | |||
| + | 一旦该软件已编译并安装后,您准备配置slapd ( 8 ) ,用于您的网站。与以前OpenLDAP的版本不同,slapd ( 8 )运行时配置在2.3 (及更高版本)是完全的允许LDAP并且可以LDIF数据使用标准的LDAP操作来管理 。LDAP配置引擎允许所有slapd的配置选项在运行中改变,一般不需要重新启动服务器以使更改生效。旧风格slapd.conf ( 5 )文件仍然是支持的,但必须转换为新的slapd配置( 5 )格式,允许运行时改变被保存。虽然旧的风格配置使用一个单一的文件,通常安装在/usr/local/etc/openldap/slapd.conf ,新的风格采用了slapd后端数据库来存储配置。配置数据库通常放在/usr/local/etc/openldap/slapd.d目录。从slapd.conf格式转换成slapd.d格式时,任何包含文件也将被集成到由此产生的配置数据库。 | ||
| + | |||
| + | 可以通过slapd ( 8 )的命令行选项指定候补的配置目录(或文件) 。本章说明配置系统的一般格式,然后详细说明了常用的配置设置。 | ||
| + | |||
| + | 注:一些后端和分布式覆盖还不支持运行时配置。在这种情况下,旧式slapd.conf ( 5 )文件必须使用。 | ||
| + | |||
| + | ===配置布局=== | ||
| + | |||
| + | slapd配置作为一个特殊的拥有预定义的规划和DIT的LDAP目录来存储。有一些特定的objectClasses用于进行全球配置选项,架构定义,后端和数据库的定义,以及各种其他项目。样本配置树如图5.1. | ||
| + | |||
| + | [http://www.openldap.org/doc/admin24/config_dit.png http://www.openldap.org/doc/admin24/config_dit.png] | ||
| + | |||
| + | 图 5.1: 样本配置树. | ||
| + | |||
| + | 其他对象可能是配置的一部分,但省略了明确的说明. | ||
| + | |||
| + | 该slapd配置配置树有一个非常特殊的结构。树的根被命名为 cn=config,并且包含全球配置设置。其他设置均包含在独立的子条目中:: | ||
| + | |||
| + | :* 动态装载模块 | ||
| + | ::这些可能只在使用了 --enable-modules 选项 configure 软件的时候需要用. | ||
| + | :* 规划定义 | ||
| + | ::cn=schema,cn=config 条目包含了系统的规划(在slapd中所有规划都是硬编码). | ||
| + | ::cn=schema,cn=config 的子条目包含从配置文件装载或运行时添加的的用户规划. | ||
| + | :* 特定后端配置 | ||
| + | :* 特定数据库配置 | ||
| + | ::Overlay被定义在数据库条目的子条目下. | ||
| + | ::数据库和Overlay也可以有其他的杂项子条目. | ||
| + | |||
| + | |||
| + | LDIF文件的通常规则适用于配置信息:以'#'字符开始的注释行会被忽略。如果一行的开始是一个空格,它被认为是延续前行(即使前行是注释)并且这个单个的空格会被删除。条目是由空白行分开的。 | ||
| + | |||
| + | config LDIF的总体布局如下: | ||
| + | <source lang="text"> | ||
| + | # 全球配置设定 | ||
| + | dn: cn=config | ||
| + | objectClass: olcGlobal | ||
| + | cn: config | ||
| + | <global config settings> | ||
| + | |||
| + | # 规划定义 | ||
| + | dn: cn=schema,cn=config | ||
| + | objectClass: olcSchemaConfig | ||
| + | cn: schema | ||
| + | <system schema> | ||
| + | |||
| + | dn: cn={X}core,cn=schema,cn=config | ||
| + | objectClass: olcSchemaConfig | ||
| + | cn: {X}core | ||
| + | <core schema> | ||
| + | |||
| + | # 额外的用户定义的规划 | ||
| + | ... | ||
| + | |||
| + | # 后端定义 | ||
| + | dn: olcBackend=<typeA>,cn=config | ||
| + | objectClass: olcBackendConfig | ||
| + | olcBackend: <typeA> | ||
| + | <backend-specific settings> | ||
| + | |||
| + | # 数据库定义 | ||
| + | dn: olcDatabase={X}<typeA>,cn=config | ||
| + | objectClass: olcDatabaseConfig | ||
| + | olcDatabase: {X}<typeA> | ||
| + | <database-specific settings> | ||
| + | |||
| + | # 随后的定义和设置 | ||
| + | ... | ||
| + | </source> | ||
| + | 一些以上所列项目在他们的名字有一个数字索引"{X}"。虽然大多数配置设置具有内在的次序依赖(即一个设置必须在另一个设定之前生效),LDAP数据库本身是无次序的。这个数字索引是用来在配置数据库强制一致性的次序,以便使所有的次序依赖被保存。在大多数情况下,并没有提供索引,它将根据条目创建的顺序自动生成。 | ||
| + | |||
| + | 配置指令被定义为一个独立属性的值。大部分用于slapd配置的属性和objectClasses在他们的名字有一个“olc”前缀 ( OpenLDAP配置)。通常在属性和旧式slapd.conf配置关键字之间有一对一的对应关系,使用关键字作为属性名称,以“olc”作前缀。 | ||
| + | |||
| + | 一个配置指令可采用参数。如果是这样,参数们由空格分开。如果参数包含空格,这个参数应包含在双引号里“像这样” 。在以下描述中,在方括号<>中的参数应被实际的文字替换 。 | ||
| + | |||
| + | 发布版包含一个配置文件例子,将被安装在/usr/local/etc/OpenLDAP目录。在/usr/local/etc/openldap/schema目录还提供了一些包含架构定义(属性类型和对象类)的文件。 | ||
| + | |||
| + | ===配置指令=== | ||
| + | |||
| + | 本节详述常用的配置指令。如需完整清单,请参阅slapd-config( 5 )帮助页面。本节将按自上而下的顺序排列配置指令,首先是全球性指令的 cn=config 项。每个指令将描述其默认值(如果有的话)和它的一个使用例子。 | ||
| + | |||
| + | ====cn=config==== | ||
| + | |||
| + | 此项目中所载的指令一般适用于把服务器作为一个整体。他们中的大多数是系统或面向连接的,而不是数据库相关的。此项目必须有olcGlobal对象。 | ||
| + | |||
| + | =====olcIdleTimeout: <integer>===== | ||
| + | |||
| + | 指定强行关闭闲置客户端连接等待的秒数。默认情况下,值为0,禁用此功能。 | ||
| + | |||
| + | =====olcLogLevel: <level>===== | ||
| + | |||
| + | 该指令规定在哪一级的调试和运行统计报表应syslogged (目前记录到syslogd ( 8 ) LOG_LOCAL4设施)。您必须配置OpenLDAP -enable-debug(默认)为工作(除了这两个统计级别,是始终启用的)。日志级别可能会被指定为整数或关键字。可使用多重记录级别并且级别是可添加的。要显示哪些层次对应于什么样的调试,以 -D? 调用 slapd 或参考下表。<level>可能的值有: | ||
| + | |||
| + | '''表 5.1: 调试级别''' | ||
| + | {|border="1" cellspacing="0" | ||
| + | !级别 !! 关键字 !! 描述 | ||
| + | |- | ||
| + | |-1 || any || 允许所有调试 | ||
| + | |- | ||
| + | |0 || || 不调试 | ||
| + | |- | ||
| + | |1 || (0x1 trace) || 跟踪函数调用 | ||
| + | |- | ||
| + | |2 || (0x2 packets) || 调试包的处理 | ||
| + | |- | ||
| + | |4 || (0x4 args) || 重度跟踪调试 | ||
| + | |- | ||
| + | |8 || (0x8 conns) || 连接管理 | ||
| + | |- | ||
| + | |16 || (0x10 BER) || 打印发送和接收的包 | ||
| + | |- | ||
| + | |32 || (0x20 filter) || 搜索过滤器的处理 | ||
| + | |- | ||
| + | |64 || (0x40 config) || 配置处理 | ||
| + | |- | ||
| + | |128 || (0x80 ACL) || 访问控制列表处理 | ||
| + | |- | ||
| + | |256 || (0x100 stats) || 连接/操作/结果的统计日志 | ||
| + | |- | ||
| + | |512 || (0x200 stats2) || 发送的条目的统计日志 | ||
| + | |- | ||
| + | |1024 || (0x400 shell) || 打印和shell后端的通信 | ||
| + | |- | ||
| + | |2048 || (0x800 parse) || 打印条目解析调试 | ||
| + | |- | ||
| + | |16384 || (0x4000 sync) || syncrepl消费者处理 | ||
| + | |- | ||
| + | |32768 || (0x8000 none) || 只显示那些不受日志级别设置影响的消息 | ||
| + | |} | ||
| + | |||
| + | 预期的日志级别可作为一个单一的整数输入,它结合了 (或运算) 预期级别(们), 包括十进制或十六进制符号, 作为一些整数的列表 (内部或运算), 或作为名字的列表,展示在括号里, 例如 | ||
| + | |||
| + | <source lang="text"> | ||
| + | olcLogLevel 129 | ||
| + | olcLogLevel 0x81 | ||
| + | olcLogLevel 128 1 | ||
| + | olcLogLevel 0x80 0x1 | ||
| + | olcLogLevel acl trace | ||
| + | </source> | ||
| + | |||
| + | 是等效的. | ||
| + | |||
| + | 例子: | ||
| + | |||
| + | olcLogLevel -1 | ||
| + | |||
| + | This will cause lots and lots of debugging information to be logged. | ||
| + | |||
| + | olcLogLevel conns filter | ||
| + | |||
| + | Just log the connection and search filter processing. | ||
| + | |||
| + | olcLogLevel none | ||
| + | |||
| + | Log those messages that are logged regardless of the configured loglevel. This differs from setting the log level to 0, when no logging occurs. At least the None level is required to have high priority messages logged. | ||
| + | |||
| + | Default: | ||
| + | |||
| + | olcLogLevel stats | ||
| + | |||
| + | Basic stats logging is configured by default. However, if no olcLogLevel is defined, no logging occurs (equivalent to a 0 level). | ||
| + | |||
| + | =====olcReferral <URI>===== | ||
| + | |||
| + | This directive specifies the referral to pass back when slapd cannot find a local database to handle a request. | ||
| + | |||
| + | Example: | ||
| + | |||
| + | olcReferral: ldap://root.openldap.org | ||
| + | |||
| + | This will refer non-local queries to the global root LDAP server at the OpenLDAP Project. Smart LDAP clients can re-ask their query at that server, but note that most of these clients are only going to know how to handle simple LDAP URLs that contain a host part and optionally a distinguished name part. | ||
| + | |||
| + | =====示例条目===== | ||
| + | |||
| + | dn: cn=config | ||
| + | objectClass: olcGlobal | ||
| + | cn: config | ||
| + | olcIdleTimeout: 30 | ||
| + | olcLogLevel: Stats | ||
| + | olcReferral: ldap://root.openldap.org | ||
| + | |||
| + | ====cn=module==== | ||
| + | |||
| + | If support for dynamically loaded modules was enabled when configuring slapd, cn=module entries may be used to specify sets of modules to load. Module entries must have the olcModuleList objectClass. | ||
| + | |||
| + | =====olcModuleLoad: <filename>===== | ||
| + | |||
| + | Specify the name of a dynamically loadable module to load. The filename may be an absolute path name or a simple filename. Non-absolute names are searched for in the directories specified by the olcModulePath directive. | ||
| + | |||
| + | =====olcModulePath: <pathspec>===== | ||
| + | |||
| + | Specify a list of directories to search for loadable modules. Typically the path is colon-separated but this depends on the operating system. | ||
| + | |||
| + | =====示例条目===== | ||
| + | |||
| + | dn: cn=module{0},cn=config | ||
| + | objectClass: olcModuleList | ||
| + | cn: module{0} | ||
| + | olcModuleLoad: /usr/local/lib/smbk5pwd.la | ||
| + | |||
| + | dn: cn=module{1},cn=config | ||
| + | objectClass: olcModuleList | ||
| + | cn: module{1} | ||
| + | olcModulePath: /usr/local/lib:/usr/local/lib/slapd | ||
| + | olcModuleLoad: accesslog.la | ||
| + | olcModuleLoad: pcache.la | ||
| + | |||
| + | ====cn=schema==== | ||
| + | |||
| + | The cn=schema entry holds all of the schema definitions that are hard-coded in slapd. As such, the values in this entry are generated by slapd so no schema values need to be provided in the config file. The entry must still be defined though, to serve as a base for the user-defined schema to add in underneath. Schema entries must have the olcSchemaConfig objectClass. | ||
| + | |||
| + | =====olcAttributeTypes: <RFC4512 Attribute Type Description>===== | ||
| + | |||
| + | This directive defines an attribute type. Please see the Schema Specification chapter for information regarding how to use this directive. | ||
| + | |||
| + | =====olcObjectClasses: <RFC4512 Object Class Description>===== | ||
| + | |||
| + | This directive defines an object class. Please see the Schema Specification chapter for information regarding how to use this directive. | ||
| + | |||
| + | =====示例条目===== | ||
| + | |||
| + | dn: cn=schema,cn=config | ||
| + | objectClass: olcSchemaConfig | ||
| + | cn: schema | ||
| + | |||
| + | dn: cn=test,cn=schema,cn=config | ||
| + | objectClass: olcSchemaConfig | ||
| + | cn: test | ||
| + | olcAttributeTypes: ( 1.1.1 | ||
| + | NAME 'testAttr' | ||
| + | EQUALITY integerMatch | ||
| + | SYNTAX 1.3.6.1.4.1.1466.115.121.1.27 ) | ||
| + | olcAttributeTypes: ( 1.1.2 NAME 'testTwo' EQUALITY caseIgnoreMatch | ||
| + | SUBSTR caseIgnoreSubstringsMatch SYNTAX 1.3.6.1.4.1.1466.115.121.1.44 ) | ||
| + | olcObjectClasses: ( 1.1.3 NAME 'testObject' | ||
| + | MAY ( testAttr $ testTwo ) AUXILIARY ) | ||
| + | |||
| + | ====具体后端指令==== | ||
| + | |||
| + | Backend directives apply to all database instances of the same type and, depending on the directive, may be overridden by database directives. Backend entries must have the olcBackendConfig objectClass. | ||
| + | |||
| + | =====olcBackend: <type>===== | ||
| + | |||
| + | This directive names a backend-specific configuration entry. <type> should be one of the supported backend types listed in Table 5.2. | ||
| + | Table 5.2: Database Backends Types Description | ||
| + | bdb Berkeley DB transactional backend | ||
| + | config Slapd configuration backend | ||
| + | dnssrv DNS SRV backend | ||
| + | hdb Hierarchical variant of bdb backend | ||
| + | ldap Lightweight Directory Access Protocol (Proxy) backend | ||
| + | ldif Lightweight Data Interchange Format backend | ||
| + | meta Meta Directory backend | ||
| + | monitor Monitor backend | ||
| + | passwd Provides read-only access to passwd(5) | ||
| + | perl Perl Programmable backend | ||
| + | shell Shell (extern program) backend | ||
| + | sql SQL Programmable backend | ||
| + | |||
| + | Example: | ||
| + | |||
| + | olcBackend: bdb | ||
| + | |||
| + | There are no other directives defined for this entry. Specific backend types may define additional attributes for their particular use but so far none have ever been defined. As such, these directives usually do not appear in any actual configurations. | ||
| + | =====示例条目===== | ||
| + | |||
| + | dn: olcBackend=bdb,cn=config | ||
| + | objectClass: olcBackendConfig | ||
| + | olcBackend: bdb | ||
| + | |||
| + | ====特定数据库==== | ||
| + | |||
| + | Directives in this section are supported by every type of database. Database entries must have the olcDatabaseConfig objectClass. | ||
| + | |||
| + | =====olcDatabase: [{<index>}]<type>===== | ||
| + | |||
| + | This directive names a specific database instance. The numeric {<index>} may be provided to distinguish multiple databases of the same type. Usually the index can be omitted, and slapd will generate it automatically. <type> should be one of the supported backend types listed in Table 5.2 or the frontend type. | ||
| + | |||
| + | The frontend is a special database that is used to hold database-level options that should be applied to all the other databases. Subsequent database definitions may also override some frontend settings. | ||
| + | |||
| + | The config database is also special; both the config and the frontend databases are always created implicitly even if they are not explicitly configured, and they are created before any other databases. | ||
| + | |||
| + | Example: | ||
| + | |||
| + | olcDatabase: bdb | ||
| + | |||
| + | This marks the beginning of a new BDB database instance. | ||
| + | |||
| + | =====olcAccess: to <what> [ by <who> [<accesslevel>] [<control>] ]+===== | ||
| + | |||
| + | This directive grants access (specified by <accesslevel>) to a set of entries and/or attributes (specified by <what>) by one or more requestors (specified by <who>). See the Access Control section of this guide for basic usage. | ||
| + | |||
| + | Note: If no olcAccess directives are specified, the default access control policy, to * by * read, allows all users (both authenticated and anonymous) read access. | ||
| + | |||
| + | Note: Access controls defined in the frontend are appended to all other databases' controls. | ||
| + | |||
| + | =====olcReadonly { TRUE | FALSE }===== | ||
| + | |||
| + | This directive puts the database into "read-only" mode. Any attempts to modify the database will return an "unwilling to perform" error. | ||
| + | |||
| + | Default: | ||
| + | |||
| + | olcReadonly: FALSE | ||
| + | |||
| + | =====olcRootDN: <DN>===== | ||
| + | |||
| + | This directive specifies the DN that is not subject to access control or administrative limit restrictions for operations on this database. The DN need not refer to an entry in this database or even in the directory. The DN may refer to a SASL identity. | ||
| + | |||
| + | Entry-based Example: | ||
| + | |||
| + | olcRootDN: "cn=Manager,dc=example,dc=com" | ||
| + | |||
| + | SASL-based Example: | ||
| + | |||
| + | olcRootDN: "uid=root,cn=example.com,cn=digest-md5,cn=auth" | ||
| + | |||
| + | See the SASL Authentication section for information on SASL authentication identities. | ||
| + | |||
| + | =====olcRootPW: <password>===== | ||
| + | |||
| + | This directive can be used to specify a password for the DN for the rootdn (when the rootdn is set to a DN within the database). | ||
| + | |||
| + | Example: | ||
| + | |||
| + | olcRootPW: secret | ||
| + | |||
| + | It is also permissible to provide a hash of the password in RFC2307 form. slappasswd(8) may be used to generate the password hash. | ||
| + | |||
| + | Example: | ||
| + | |||
| + | olcRootPW: {SSHA}ZKKuqbEKJfKSXhUbHG3fG8MDn9j1v4QN | ||
| + | |||
| + | The hash was generated using the command slappasswd -s secret. | ||
| + | |||
| + | =====olcSizeLimit: <integer>===== | ||
| + | |||
| + | This directive specifies the maximum number of entries to return from a search operation. | ||
| + | |||
| + | Default: | ||
| + | |||
| + | olcSizeLimit: 500 | ||
| + | |||
| + | See the Limits section of this guide and slapd-config(5) for more details. | ||
| + | |||
| + | =====olcSuffix: <dn suffix>===== | ||
| + | |||
| + | This directive specifies the DN suffix of queries that will be passed to this backend database. Multiple suffix lines can be given, and usually at least one is required for each database definition. (Some backend types, such as frontend and monitor use a hard-coded suffix which may not be overridden in the configuration.) | ||
| + | |||
| + | Example: | ||
| + | |||
| + | olcSuffix: "dc=example,dc=com" | ||
| + | |||
| + | Queries with a DN ending in "dc=example,dc=com" will be passed to this backend. | ||
| + | |||
| + | Note: When the backend to pass a query to is selected, slapd looks at the suffix value(s) in each database definition in the order in which they were configured. Thus, if one database suffix is a prefix of another, it must appear after it in the configuration. | ||
| + | |||
| + | =====olcSyncrepl===== | ||
| + | <source lang="ini"> | ||
| + | olcSyncrepl: rid=<replica ID> | ||
| + | provider=ldap[s]://<hostname>[:port] | ||
| + | [type=refreshOnly|refreshAndPersist] | ||
| + | [interval=dd:hh:mm:ss] | ||
| + | [retry=[<retry interval> <# of retries>]+] | ||
| + | searchbase=<base DN> | ||
| + | [filter=<filter str>] | ||
| + | [scope=sub|one|base] | ||
| + | [attrs=<attr list>] | ||
| + | [attrsonly] | ||
| + | [sizelimit=<limit>] | ||
| + | [timelimit=<limit>] | ||
| + | [schemachecking=on|off] | ||
| + | [bindmethod=simple|sasl] | ||
| + | [binddn=<DN>] | ||
| + | [saslmech=<mech>] | ||
| + | [authcid=<identity>] | ||
| + | [authzid=<identity>] | ||
| + | [credentials=<passwd>] | ||
| + | [realm=<realm>] | ||
| + | [secprops=<properties>] | ||
| + | [starttls=yes|critical] | ||
| + | [tls_cert=<file>] | ||
| + | [tls_key=<file>] | ||
| + | [tls_cacert=<file>] | ||
| + | [tls_cacertdir=<path>] | ||
| + | [tls_reqcert=never|allow|try|demand] | ||
| + | [tls_ciphersuite=<ciphers>] | ||
| + | [tls_crlcheck=none|peer|all] | ||
| + | [logbase=<base DN>] | ||
| + | [logfilter=<filter str>] | ||
| + | [syncdata=default|accesslog|changelog] | ||
| + | </source> | ||
| + | 这个指令定义当前数据库作为一个主服务器内容的复制,通过当前的slapd(8) 建立一个运行syncrepl复制引擎的复制消费者站点. 主数据库由provider参数定位于复制提供者站点. 复制数据库使用LDAP内容同步协议保持对主服务器内容的更新. 关于协议的更多信息参见 RFC4533. | ||
| + | |||
| + | The rid parameter is used for identification of the current syncrepl directive within the replication consumer server, where <replica ID> uniquely identifies the syncrepl specification described by the current syncrepl directive. <replica ID> is non-negative and is no more than three decimal digits in length. | ||
| + | |||
| + | The provider parameter specifies the replication provider site containing the master content as an LDAP URI. The provider parameter specifies a scheme, a host and optionally a port where the provider slapd instance can be found. Either a domain name or IP address may be used for <hostname>. Examples are ldap://provider.example.com:389 or ldaps://192.168.1.1:636. If <port> is not given, the standard LDAP port number (389 or 636) is used. Note that the syncrepl uses a consumer-initiated protocol, and hence its specification is located at the consumer site, whereas the replica specification is located at the provider site. syncrepl and replica directives define two independent replication mechanisms. They do not represent the replication peers of each other. | ||
| + | |||
| + | The content of the syncrepl replica is defined using a search specification as its result set. The consumer slapd will send search requests to the provider slapd according to the search specification. The search specification includes searchbase, scope, filter, attrs, attrsonly, sizelimit, and timelimit parameters as in the normal search specification. The searchbase parameter has no default value and must always be specified. The scope defaults to sub, the filter defaults to (objectclass=*), attrs defaults to "*,+" to replicate all user and operational attributes, and attrsonly is unset by default. Both sizelimit and timelimit default to "unlimited", and only positive integers or "unlimited" may be specified. | ||
| + | |||
| + | The LDAP Content Synchronization protocol has two operation types: refreshOnly and refreshAndPersist. The operation type is specified by the type parameter. In the refreshOnly operation, the next synchronization search operation is periodically rescheduled at an interval time after each synchronization operation finishes. The interval is specified by the interval parameter. It is set to one day by default. In the refreshAndPersist operation, a synchronization search remains persistent in the provider slapd instance. Further updates to the master replica will generate searchResultEntry to the consumer slapd as the search responses to the persistent synchronization search. | ||
| + | |||
| + | If an error occurs during replication, the consumer will attempt to reconnect according to the retry parameter which is a list of the <retry interval> and <# of retries> pairs. For example, retry="60 10 300 3" lets the consumer retry every 60 seconds for the first 10 times and then retry every 300 seconds for the next three times before stop retrying. + in <# of retries> means indefinite number of retries until success. | ||
| + | |||
| + | The schema checking can be enforced at the LDAP Sync consumer site by turning on the schemachecking parameter. If it is turned on, every replicated entry will be checked for its schema as the entry is stored into the replica content. Every entry in the replica should contain those attributes required by the schema definition. If it is turned off, entries will be stored without checking schema conformance. The default is off. | ||
| + | |||
| + | The binddn parameter gives the DN to bind as for the syncrepl searches to the provider slapd. It should be a DN which has read access to the replication content in the master database. | ||
| + | |||
| + | The bindmethod is simple or sasl, depending on whether simple password-based authentication or SASL authentication is to be used when connecting to the provider slapd instance. | ||
| + | |||
| + | Simple authentication should not be used unless adequate data integrity and confidentiality protections are in place (e.g. TLS or IPsec). Simple authentication requires specification of binddn and credentials parameters. | ||
| + | |||
| + | SASL authentication is generally recommended. SASL authentication requires specification of a mechanism using the saslmech parameter. Depending on the mechanism, an authentication identity and/or credentials can be specified using authcid and credentials, respectively. The authzid parameter may be used to specify an authorization identity. | ||
| + | |||
| + | The realm parameter specifies a realm which a certain mechanisms authenticate the identity within. The secprops parameter specifies Cyrus SASL security properties. | ||
| + | |||
| + | The starttls parameter specifies use of the StartTLS extended operation to establish a TLS session before authenticating to the provider. If the critical argument is supplied, the session will be aborted if the StartTLS request fails. Otherwise the syncrepl session continues without TLS. Note that the main slapd TLS settings are not used by the syncrepl engine; by default the TLS parameters from a ldap.conf(5) configuration file will be used. TLS settings may be specified here, in which case any ldap.conf(5) settings will be completely ignored. | ||
| + | |||
| + | Rather than replicating whole entries, the consumer can query logs of data modifications. This mode of operation is referred to as delta syncrepl. In addition to the above parameters, the logbase and logfilter parameters must be set appropriately for the log that will be used. The syncdata parameter must be set to either "accesslog" if the log conforms to the slapo-accesslog(5) log format, or "changelog" if the log conforms to the obsolete changelog format. If the syncdata parameter is omitted or set to "default" then the log parameters are ignored. | ||
| + | |||
| + | The syncrepl replication mechanism is supported by the bdb and hdb backends. | ||
| + | |||
| + | See the LDAP Sync Replication chapter of this guide for more information on how to use this directive. | ||
| + | |||
| + | =====olcTimeLimit: <integer>===== | ||
| + | |||
| + | This directive specifies the maximum number of seconds (in real time) slapd will spend answering a search request. If a request is not finished in this time, a result indicating an exceeded timelimit will be returned. | ||
| + | |||
| + | Default: | ||
| + | |||
| + | olcTimeLimit: 3600 | ||
| + | |||
| + | See the Limits section of this guide and slapd-config(5) for more details. | ||
| + | =====olcUpdateref: <URL>===== | ||
| + | |||
| + | This directive is only applicable in a slave slapd. It specifies the URL to return to clients which submit update requests upon the replica. If specified multiple times, each URL is provided. | ||
| + | |||
| + | Example: | ||
| + | |||
| + | olcUpdateref: ldap://master.example.net | ||
| + | |||
| + | =====Sample Entries===== | ||
| + | |||
| + | dn: olcDatabase=frontend,cn=config | ||
| + | objectClass: olcDatabaseConfig | ||
| + | objectClass: olcFrontendConfig | ||
| + | olcDatabase: frontend | ||
| + | olcReadOnly: FALSE | ||
| + | |||
| + | dn: olcDatabase=config,cn=config | ||
| + | objectClass: olcDatabaseConfig | ||
| + | olcDatabase: config | ||
| + | olcRootDN: cn=Manager,dc=example,dc=com | ||
| + | |||
| + | ====BDB和HDB数据库指令==== | ||
| + | |||
| + | Directives in this category apply to both the BDB and the HDB database. They are used in an olcDatabase entry in addition to the generic database directives defined above. For a complete reference of BDB/HDB configuration directives, see slapd-bdb(5). In addition to the olcDatabaseConfig objectClass, BDB and HDB database entries must have the olcBdbConfig and olcHdbConfig objectClass, respectively. | ||
| + | |||
| + | =====olcDbDirectory: <directory>===== | ||
| + | |||
| + | This directive specifies the directory where the BDB files containing the database and associated indices live. | ||
| + | |||
| + | Default: | ||
| + | |||
| + | olcDbDirectory: /usr/local/var/openldap-data | ||
| + | |||
| + | =====olcDbCachesize: <integer>===== | ||
| + | |||
| + | This directive specifies the size in entries of the in-memory cache maintained by the BDB backend database instance. | ||
| + | |||
| + | Default: | ||
| + | |||
| + | olcDbCachesize: 1000 | ||
| + | |||
| + | =====olcDbCheckpoint: <kbyte> <min>===== | ||
| + | |||
| + | This directive specifies how often to checkpoint the BDB transaction log. A checkpoint operation flushes the database buffers to disk and writes a checkpoint record in the log. The checkpoint will occur if either <kbyte> data has been written or <min> minutes have passed since the last checkpoint. Both arguments default to zero, in which case they are ignored. When the <min> argument is non-zero, an internal task will run every <min> minutes to perform the checkpoint. See the Berkeley DB reference guide for more details. | ||
| + | |||
| + | Example: | ||
| + | |||
| + | olcDbCheckpoint: 1024 10 | ||
| + | |||
| + | =====olcDbConfig: <DB_CONFIG setting>===== | ||
| + | |||
| + | This attribute specifies a configuration directive to be placed in the DB_CONFIG file of the database directory. At server startup time, if no such file exists yet, the DB_CONFIG file will be created and the settings in this attribute will be written to it. If the file exists, its contents will be read and displayed in this attribute. The attribute is multi-valued, to accommodate multiple configuration directives. No default is provided, but it is essential to use proper settings here to get the best server performance. | ||
| + | |||
| + | Any changes made to this attribute will be written to the DB_CONFIG file and will cause the database environment to be reset so the changes can take immediate effect. If the environment cache is large and has not been recently checkpointed, this reset operation may take a long time. It may be advisable to manually perform a single checkpoint using the Berkeley DB db_checkpoint utility before using LDAP Modify to change this attribute. | ||
| + | |||
| + | Example: | ||
| + | |||
| + | olcDbConfig: set_cachesize 0 10485760 0 | ||
| + | olcDbConfig: set_lg_bsize 2097512 | ||
| + | olcDbConfig: set_lg_dir /var/tmp/bdb-log | ||
| + | olcDbConfig: set_flags DB_LOG_AUTOREMOVE | ||
| + | |||
| + | In this example, the BDB cache is set to 10MB, the BDB transaction log buffer size is set to 2MB, and the transaction log files are to be stored in the /var/tmp/bdb-log directory. Also a flag is set to tell BDB to delete transaction log files as soon as their contents have been checkpointed and they are no longer needed. Without this setting the transaction log files will continue to accumulate until some other cleanup procedure removes them. See the Berkeley DB documentation for the db_archive command for details. For a complete list of Berkeley DB flags please see - http://www.oracle.com/technology/documentation/berkeley-db/db/api_c/env_set_flags.html | ||
| + | |||
| + | Ideally the BDB cache must be at least as large as the working set of the database, the log buffer size should be large enough to accommodate most transactions without overflowing, and the log directory must be on a separate physical disk from the main database files. And both the database directory and the log directory should be separate from disks used for regular system activities such as the root, boot, or swap filesystems. See the FAQ-o-Matic and the Berkeley DB documentation for more details. | ||
| + | |||
| + | =====olcDbNosync: { TRUE | FALSE }===== | ||
| + | |||
| + | This option causes on-disk database contents to not be immediately synchronized with in memory changes upon change. Setting this option to TRUE may improve performance at the expense of data integrity. This directive has the same effect as using | ||
| + | |||
| + | olcDbConfig: set_flags DB_TXN_NOSYNC | ||
| + | |||
| + | =====olcDbIDLcacheSize: <integer>===== | ||
| + | |||
| + | Specify the size of the in-memory index cache, in index slots. The default is zero. A larger value will speed up frequent searches of indexed entries. The optimal size will depend on the data and search characteristics of the database, but using a number three times the entry cache size is a good starting point. | ||
| + | |||
| + | Example: | ||
| + | |||
| + | olcDbIDLcacheSize: 3000 | ||
| + | |||
| + | =====olcDbIndex: {<attrlist> | default} [pres,eq,approx,sub,none]===== | ||
| + | |||
| + | This directive specifies the indices to maintain for the given attribute. If only an <attrlist> is given, the default indices are maintained. The index keywords correspond to the common types of matches that may be used in an LDAP search filter. | ||
| + | |||
| + | Example: | ||
| + | |||
| + | olcDbIndex: default pres,eq | ||
| + | olcDbIndex: uid | ||
| + | olcDbIndex: cn,sn pres,eq,sub | ||
| + | olcDbIndex: objectClass eq | ||
| + | |||
| + | The first line sets the default set of indices to maintain to present and equality. The second line causes the default (pres,eq) set of indices to be maintained for the uid attribute type. The third line causes present, equality, and substring indices to be maintained for cn and sn attribute types. The fourth line causes an equality index for the objectClass attribute type. | ||
| + | |||
| + | There is no index keyword for inequality matches. Generally these matches do not use an index. However, some attributes do support indexing for inequality matches, based on the equality index. | ||
| + | |||
| + | A substring index can be more explicitly specified as subinitial, subany, or subfinal, corresponding to the three possible components of a substring match filter. A subinitial index only indexes substrings that appear at the beginning of an attribute value. A subfinal index only indexes substrings that appear at the end of an attribute value, while subany indexes substrings that occur anywhere in a value. | ||
| + | |||
| + | Note that by default, setting an index for an attribute also affects every subtype of that attribute. E.g., setting an equality index on the name attribute causes cn, sn, and every other attribute that inherits from name to be indexed. | ||
| + | |||
| + | By default, no indices are maintained. It is generally advised that minimally an equality index upon objectClass be maintained. | ||
| + | |||
| + | olcDbindex: objectClass eq | ||
| + | |||
| + | Additional indices should be configured corresponding to the most common searches that are used on the database. Presence indexing should not be configured for an attribute unless the attribute occurs very rarely in the database, and presence searches on the attribute occur very frequently during normal use of the directory. Most applications don't use presence searches, so usually presence indexing is not very useful. | ||
| + | |||
| + | If this setting is changed while slapd is running, an internal task will be run to generate the changed index data. All server operations can continue as normal while the indexer does its work. If slapd is stopped before the index task completes, indexing will have to be manually completed using the slapindex tool. | ||
| + | |||
| + | =====olcDbLinearIndex: { TRUE | FALSE }===== | ||
| + | |||
| + | If this setting is TRUE slapindex will index one attribute at a time. The default settings is FALSE in which case all indexed attributes of an entry are processed at the same time. When enabled, each indexed attribute is processed individually, using multiple passes through the entire database. This option improves slapindex performance when the database size exceeds the BDB cache size. When the BDB cache is large enough, this option is not needed and will decrease performance. Also by default, slapadd performs full indexing and so a separate slapindex run is not needed. With this option, slapadd does no indexing and slapindex must be used. | ||
| + | |||
| + | =====olcDbMode: { <octal> | <symbolic> }===== | ||
| + | |||
| + | This directive specifies the file protection mode that newly created database index files should have. This can be in the form 0600 or -rw------- | ||
| + | |||
| + | Default: | ||
| + | |||
| + | olcDbMode: 0600 | ||
| + | |||
| + | =====olcDbSearchStack: <integer>===== | ||
| + | |||
| + | Specify the depth of the stack used for search filter evaluation. Search filters are evaluated on a stack to accommodate nested AND / OR clauses. An individual stack is allocated for each server thread. The depth of the stack determines how complex a filter can be evaluated without requiring any additional memory allocation. Filters that are nested deeper than the search stack depth will cause a separate stack to be allocated for that particular search operation. These separate allocations can have a major negative impact on server performance, but specifying too much stack will also consume a great deal of memory. Each search uses 512K bytes per level on a 32-bit machine, or 1024K bytes per level on a 64-bit machine. The default stack depth is 16, thus 8MB or 16MB per thread is used on 32 and 64 bit machines, respectively. Also the 512KB size of a single stack slot is set by a compile-time constant which may be changed if needed; the code must be recompiled for the change to take effect. | ||
| + | |||
| + | Default: | ||
| + | |||
| + | olcDbSearchStack: 16 | ||
| + | |||
| + | =====olcDbShmKey: <integer>===== | ||
| + | |||
| + | Specify a key for a shared memory BDB environment. By default the BDB environment uses memory mapped files. If a non-zero value is specified, it will be used as the key to identify a shared memory region that will house the environment. | ||
| + | |||
| + | Example: | ||
| + | |||
| + | olcDbShmKey: 42 | ||
| + | |||
| + | =====示例条目===== | ||
| + | <source lang="ini"> | ||
| + | dn: olcDatabase=hdb,cn=config | ||
| + | objectClass: olcDatabaseConfig | ||
| + | objectClass: olcHdbConfig | ||
| + | olcDatabase: hdb | ||
| + | olcSuffix: "dc=example,dc=com" | ||
| + | olcDbDirectory: /usr/local/var/openldap-data | ||
| + | olcDbCacheSize: 1000 | ||
| + | olcDbCheckpoint: 1024 10 | ||
| + | olcDbConfig: set_cachesize 0 10485760 0 | ||
| + | olcDbConfig: set_lg_bsize 2097152 | ||
| + | olcDbConfig: set_lg_dir /var/tmp/bdb-log | ||
| + | olcDbConfig: set_flags DB_LOG_AUTOREMOVE | ||
| + | olcDbIDLcacheSize: 3000 | ||
| + | olcDbIndex: objectClass eq | ||
| + | </source> | ||
==复制== | ==复制== | ||
| 第20行: | 第1,173行: | ||
====LDAP同步复制==== | ====LDAP同步复制==== | ||
| − | LDAP同步复制引擎, 简称syncrepl, 是一个消费方的复制引擎,能让消费者服务器维护一个抽取片断的影子副本. 一个syncrepl引擎以slapd的一个线程的方式驻留在消费者那里. | + | LDAP同步复制引擎, 简称syncrepl, 是一个消费方的复制引擎,能让消费者服务器维护一个抽取片断的影子副本. 一个syncrepl引擎以slapd的一个线程的方式驻留在消费者那里. 它建立和维护一个消费者复制,方法是连接一个复制提供者去执行初始化DIT内容载荷以及接下来的定期的内容拉取或及时根据内容变更来更新。 |
| − | Syncrepl | + | Syncrepl 使用LDAP内容同步协议(或简称 LDAP Sync) 作为复制同步协议. LDAP Sync 提供一个有状态的复制,它同时支持拉模式和推模式同步并且不要求使用历史存储. 在拉模式复制下消费者定期拉提供者服务器的内容来更新. 在推模式复制下消费者监听提供者实时发送的更新. 因为协议不要求历史存储, 提供者不需要维护任何它接收到的更新的日志. (注意syncrepl引擎是可扩展的,并支持未来新增的复制协议.) |
| − | + | Syncrepl通过维护和交换同步cookies来保持对复制内容的状态的跟踪. 因为syncrepl消费者和提供者维护它们的内容状态, 消费者可以拉取提供者的内容来执行增量同步,只要请求那些最新的提供者内容条目。 Syncrepl也通过维护复制状态方便了复制的管理. 消费者复制可以在任何同步状态下从一个消费方或一个提供方的备份来构建. Syncrepl能自动重新同步消费者复制到和当前的提供者内容一致的最新状态. | |
| − | + | Syncrepl同时支持拉模式和推模式同步. 在它的基本的 refreshOnly 同步模式下, 提供者使用基于拉模式的同步,这里消费者服务器不需要被跟踪并且不维护历史信息. 需要提供者处理的定期的拉请求信息,包含在请求本身的同步cookie里面。为了优化基于拉模式的同步, syncrepl把LDAP同步协议的当前阶段当成它的删除阶段一样处理, 而不是频繁地回滚完全重载. 为了更好地优化基于拉模式的同步, 提供者可以维护一个按范围划分的会话日志作为历史存储. 在它的 refreshAndPersist 同步模式, 提供者使用基于推模式的同步. 提供者维护对请求了一个持久性搜索的消费者服务器的跟踪,并且当提供者复制内容修改的时候向它们发送必要的更新. | |
| − | + | 有了syncrepl, 如果消费者服务器有对被复制的DIT片断的适当的操作权限,一个消费者服务器可以建立一个复制而不修改提供者的配置并且不需要重新启动提供者服务器. 消费者服务器可以停止复制,也不需要提供方的任何变更和重启. | |
| − | + | Syncrepl支持局部的,稀疏的和片断复制. 影子DIT片断由一个标准通用搜索来定义,包括基础,范围,过滤条件,和属性列表. 复制内容也受限于syncrepl复制连接的绑定用户的操作权限. | |
=====LDAP内容同步协议===== | =====LDAP内容同步协议===== | ||
| − | + | LDAP同步协议允许一个客户端维护DIT片段的一个同步副本。LDAP同步操作的定义是一套控制,以及扩展LDAP搜索操作的其它协议元素。本节仅简单介绍LDAP内容同步协议。欲了解更多信息,请参阅RFC4533 。 | |
| − | + | ||
| − | + | ||
| − | + | LDAP同步协议支持拉和监听变更,通过定义两个各不相同的同步操作: refreshOnly和refreshAndPersist 。拉是由refreshOnly操作实现的。消费者使用一个LDAP搜索请求拉提供者,附带LDAP同步控制。消费者副本通过使用传回搜索到的信息实现拉取, 来从供应商副本同步。提供者在正常搜索时,搜索行动结束返回SearchResultDone,来表示完成搜索。监听是由refreshAndPersist操作实施的。顾名思义,它首先是一个搜索,如refreshOnly 。不是在返回所有目前搜索条件相匹配的条目后就完成搜索,而是同步搜索仍然保持供应商的持久化。随后供应商的同步内容更新产生额外的条目更新发送给消费者。 | |
| − | + | refreshOnly操作和refreshAndPersist操作的刷新阶段,可以在当前阶段或删除阶段执行。 | |
| − | + | 在当前阶段,提供者发送自上次同步以来搜索范围内更新的条目给消费者。提供者发送更新的条目的所有请求的属性,不论它们改变与否。对于每个仍然保持不变范围的条目,提供者发送一个当前的消息,只包含条目的名称和代表"当前"状态的同步控制。当前消息不包含条目的任何属性。在消费者收到所有更新和当前条目之后,它能够可靠地确定新的消费者副本,通过增加那些条目供应商新增的条目,和替换那些供应商修改的条目,并删除消费副本中没有更新过也没有被提供者指定为"当前"的条目。 | |
| − | + | 更新条目的传播在删除阶段和在当前阶段是一样的。提供者发送搜索范围内自上次同步以来更新的条目的所有请求的属性,给消费者。在删除阶段,无论如何,供应商为搜索范围内每个删除的条目发送一个删除消息,而不是发送当前消息。删除消息只包含条目的名称代表"删除"状态和同步控制。新的消费副本的决定可根据附加在SearchResultEntry的同步控制信息来增加,修改和删除条目。 | |
| − | + | 如果LDAP同步提供者维护了一个历史存储,而且可以确定哪些条目的范围超出了自上次同步时间以来的消费者副本,供应商可以使用删除阶段。如果供应商不保持任何记录存储,无法从历史存储确定范围之外的条目,或存储的历史并不包括消费者的过时的同步状态,供应商应利用当前阶段。比起全部内容重载产生的同步通信来,使用当前阶段是更有效的。为了更好的减少同步他通讯量,LDAP同步协议还提供了一些优化,如标准化entryUUIDs的传输和一个单一syncIdSet讯息中传送多种entryUUIDs 。 | |
| − | + | 在refreshOnly同步的结尾,在同步完成之后,提供者发送一个同步cookie到消费者,作为消费者副本的一个状态指标。当消费者向供应商请求下次的增量同步时,它将展示收到的Cookie。 | |
| + | |||
| + | 当使用 refreshAndPersist同步时,提供者在刷新阶段的结尾发送一个同步Cookie,通过发送一个同步信息消息refreshDone =为TRUE 。它还发送一个同步的Cookie附加到同步搜索的持久化阶段产生的SearchResultEntry消息中。在持久化阶段,提供者还可以发送一个同步信息,包含同步的Cookie,在任何提供者要更新消费端状态指标的时候。 | ||
| − | + | 在LDAP同步协议,条目具有唯一的entryUUID属性值。它可以作为条目的一个可靠的标识符。条目的DN,另一方面,可随时间变化,因此不能被视为可靠的标识符。entryUUID附在每个SearchResultEntry或SearchResultReference上作为同步控制的一个部分。 | |
=====Syncrepl细节===== | =====Syncrepl细节===== | ||
2010年6月9日 (三) 18:46的最后版本
本文的英文原文来自OpenLDAP Software 2.4 Administrator's Guide
先翻译快速开始指南和目录复制。
前言
版权
版权所有1998-2008 ,OpenLDAP基金会,保留所有权利。
版权所有1992-1996年,密歇根大学的Regents,保留所有权利。
本文被视为OpenLDAP软件的一部分. 本文遵从OpenLDAP软件版权声明和OpenLDAP公开许可的第四款的条件. 完整的声明和相关的许可可以分别在附录K和L看到.
OpenLDAP软件和本文的一部分可能是来自其他各方和/或受到其他版权限制。单独的源文件应该有额外的版权声明。
本文的范围
本文为在UNIX (以及类似UNIX)系统上安装OpenLDAP 软件2.4版 (http://www.openldap.org/software/)提供一个指南. 本文的目标读者是基本了解基于LDAP的目录服务的有经验的系统管理员.
本文件是用来与其他由软件包以及该项目的网站( http://www.OpenLDAP.org/ )上提供的OpenLDAP信息资源配合使用的。该网站的有很多来源.
OpenLDAP 资源
致谢
OpenLDAP项目是一个由志愿者组成的团队。没有他们贡献的时间和精力本文是不可能的。
在OpenLDAP项目还要感谢美国密西根大学的LDAP团队对于LDAP软件和信息的建设,OpenLDAP软件是建立在它的基础上的。本文件是基于密歇根大学的以下文档而来的: SLAPD和SLURPD管理员指南。
修正案
对本文的建议改进和更正应使用OpenLDAP问题跟踪系统( http://www.openldap.org/its/ )提交 。
关于本文
这份文件使用Ian Clatworthy开发的简单文件格式(SDF)文件系统( http://search.cpan.org/src/IANC/sdf-2.001/doc/catalog.html )。SDF工具可以从CPAN ( http://search.cpan.org/search?query=SDF&mode=dist )得到。
介绍OpenLDAP目录服务
本文描述如何编译,配置,以及操作OpenLDAP软件来提供目录服务. 这包括如何配置和运行独立的LDAP守护进程, slapd(8). 它对于新的和有经验的管理人员是一样的。 本节提供了一个基本的目录服务的介绍,尤其是slapd(8)所提供的目录服务的介绍. 这只是提供足够的信息,以便人们开始了解的LDAP , X.500和目录服务。
什么是目录服务?
目录是一个专门的数据库,专门用于搜索和浏览,另外也支持基本的查询和更新功能。
注意: 目录被一些人视为仅仅是一个优化了读取操作的数据库。这一定义,往最好了说,是过于简单化了。
目录往往包含描述性的,基于属性的信息和支持先进的过滤功能. 目录一般不支持被设计用于处理大批量复杂更新的数据库管理系统的复杂交易或回滚计划. 目录的更新通常是简单的全有或全无的变更,如果变更被允许的话。目录一般都调整为快速反应大批量查找或搜索操作. 它们可能有能力复制广泛的信息,以提高可用性和可靠性,同时降低响应时间. 当复制目录信息时,临时的复制品之间的不一致性可能可以接受,只要矛盾及时得到解决.
有许多不同的方式提供一个目录服务. 不同的方法允许不同种类的信息存储在目录中,对于信息可以如何转发,查询和更新,以及如何保护未经授权的访问,等有不同的要求. 一些目录服务是本地的,提供服务给一个限制的范围内(例如,一台机器的finger服务). 其他服务是全球性的,提供服务给更广泛的范围内(例如,整个互联网) 。全球服务通常是分散的,也就是说,它们包含的数据是分散在许多机器,所有这些合作来提供目录服务. 通常情况下一个全球性的服务定义了一个统一的名字空间,提供同一视图的数据,无论您身在何处和数据本身有何关系。
一个网站目录,如开放式目录管理项目<http://dmoz.org>提供的 ,就是一个很好的目录服务例子. 这些服务把网页目录化,并专门设计用于支持浏览和搜索。
虽然有些人认为,因特网的域名系统( DNS )是一个例子,一个全球分布式目录服务,但是DNS是不能浏览或搜寻的. 它更准确的描述是一个全球型的分布查找服务.
什么是LDAP?
LDAP表示轻型目录访问协议. 顾名思义,它是一个轻量级协议,用于访问目录服务,特别是基于X.500的目录服务. LDAP运行在TCP / IP或其他面向连接的传输服务. LDAP是一个IETF标准跟踪协议,在“轻量级目录访问协议( LDAP )技术规范路线图”RFC4510中被指定。
本节概述了从用户的角度来看LDAP的样子。
什么样的信息可以存储在目录? LDAP信息模型是基于条目的. 一个条目是一个属性的集合,有一个全球唯一的识别名( DN ). DN用于明白无误地标识条目. 每个条目的属性有一个类型和一个或多个值. 该类型通常是可记忆的字符串,如“ cn ”就是标识通用名称,或“电子邮件”就是电子邮件地址。 值的语法依赖于属性类型. 例如, 一个 cn 属性可以包含一个值 Babs Jensen. 一个 mail 属性可以包含值"babs@example.com". 一个 jpegPhoto 属性将包含一个JPEG (binary) 格式的照片.
信息如何组织? 在LDAP, 目录条目都被排列在一个分层树形结构。传统上,这种结构反映了地域和/或组织界限. 代表国家的条目出现在树的顶端。它们下面是代表州和国家组织的条目. 再下面可能是代表组织单位,人,打印机,文档,或只是任何你你能想象到的东西. 图1.1所示的LDAP目录树中使用传统的命名。
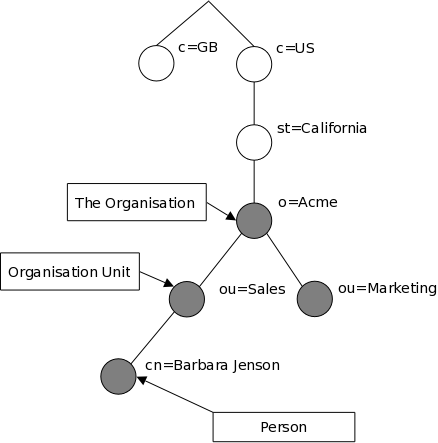
图 1.1: LDAP 目录树 (传统的命名)
树也可以根据互联网域名组主。这种命名方式正越来越受欢迎,因为它允许使用DNS为目录服务定位 。图1.2所示的LDAP目录树中使用基于域的命名。
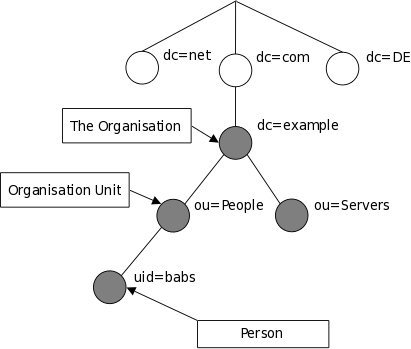
图 1.2: LDAP 目录树(Internet命名)
此外,可让您的LDAP控制在一个条目中哪个属性是必需的和允许的,通过使用一种特殊属性objectClass。objectClass属性的值确定条目必须遵守的架构规则。
信息是如何引用的的? 一个条目所引用的辨别名称,是构造于名字本身(称为相对辨别名称Relative Distinguished Name或RDN )再串连其祖先条目的名字。 例如, 在上面Internet命名例子里的条目 Barbara Jensen 有一个 RDN 为 uid=babs 和一个 DN 为 uid=babs,ou=People,dc=example,dc=com. 全 DN 格式在 RFC4514 中的 "LDAP: String Representation of Distinguished Names."有描述.
如何访问信息? LDAP定义了查问和更新目录的操作. 提供的操作包括,从一个目录增加和删除一个条目,变更一个已存在的条目,以及变更一个条目的名字. 尽管,绝大部分时间, LDAP 是用于在目录中搜索信息. LDAP搜索操作允许目录的一些部分被搜索以寻找那些满足搜索过滤器规定的条件的条目. 可以请求每个和要求相匹配的条目的信息。
例如, 你可以在 dc=example,dc=com之下的整个目录树,搜索一个人,他的名字是 Barbara Jensen, 接收每个发现的条目的 email 地址. LDAP 让你很简单地完成这件事. 或者你可能想直接在st=California,c=US下搜索, organizations 为Acme 的所有条目的名字以及传真号码. LDAP 也能让你做到. 下一节对于你能用LDAP做什么和它如何帮助你做更详细的描述.
如何从未授权的访问中保护信息? 一些目录服务不提供保护, 允许任何人查看信息. LDAP提供了给客户一个机制,向一个目录服务器验证或保护他的标识,提供了丰富的访问控制方法来保护服务器包含的信息. LDAP也支持数据安全 (完整性和保密性) 服务.
什么时候我应该使用LDAP?
这是个非常好的问题. 通常,当你需要通过标准化的方法访问集中化管理和存储的数据时,你应该使用一个目录服务器.
工业界一些常见(但不限于此)的例子如下:
- 机器验证
- 用户验证
- 用户/系统 组
- 地址簿
- 组织机构表
- 资产跟踪
- 电话信息存储
- 用户资源管理
- E-mail地址查找
- 应用配置存储
- PBX配置存储
- 其他.....
虽然有各种基于标准的分布式规划文件, 但是你总是可以建立自己的规划规范.
你总是可以有新的办法来使用目录和应用LDAP原理来解决特定的问题, 所以这个问题不存在一个简单的答案.
如果有任何疑问, 加入常见的 LDAP 论坛来参加非商业性的讨论和获得关于LDAP的信息: http://www.umich.edu/~dirsvcs/ldap/mailinglist.html
什么时候我不应使用LDAP?
当你开始发现自己用目录来做你需要做的事情的时候很别扭, 就可能需要重新设计了(译者:这不等于没说吗?). 或者你只是需要一个应用来使用和操作你的数据(关于 LDAP vs RDBMS, 参见 LDAP vs RDBMS 节).
当LDAP对某项工作很合适的时候,很明显就能看出来(译者:还是白说啊)。
LDAP是如何工作的?
LDAP采用客户-服务器模式. 包含在一个或多个LDAP服务器中的数据组成了目录信息树(DIT). 客户端连接到服务器然后问一个问题. 服务器返回一个应答和/或一个指针告诉客户端去哪里获得更多的信息 (通常是另一台 LDAP 服务器). 客户端连接哪台LDAP服务器不重要, 目录的视图看起来都一样; 一个提交到某台LDAP服务器的名字在另一台LDAP服务器上也将指向相同的条目. 这是全球目录服务的一个重要功能.
关于X.500?
技术上来讲, LDAP是一个针对X.500目录服务(OSI目录服务)的目录访问协议. 起初, LDAP客户端通过网关访问 X.500 目录服务. 客户端和网关之间跑的是LDAP,而网关和X.500服务之间跑的是 X.500 的 目录访问协议 (DAP) . DAP是一个重量级的协议,它操作完整的OSI协议栈并且需要大量的计算资源. LDAP设计成通过TCP/IP操作并以非常少的开销来提供DAP的大部分功能.
虽然 LDAP 仍被用于通过网关访问 X.500 目录服务, LDAP 现在更常见的是直接在X.500服务器上实现.
标准的 LDAP 守护进程, 或曰 slapd(8), 可以被视为一个轻量级的 X.500 目录服务. 也就是说, 它既不由 X.500's DAP 实现,也不支持完整的 X.500 模型.
如果你以及功能运行了一个 X.500 DAP 服务并且你想继续这么干, 可能你不用读这本指南了. 这份指南全部是关于通过 slapd(8)运行 LDAP , 而不是运行 X.500 DAP. 如果你没有运行 X.500 DAP, 希望停止运行 X.500 DAP, 或最近没有打算运行 X.500 DAP, 请继续.
从一个 LDAP 目录服务器复制数据到一个 X.500 DAP DSA 是有可能的. 这需要一个 LDAP/DAP 网关. OpenLDAP软件不包含这样一个网关.
LDAPv2和LDAPv3之间有何不同?
LDAPv3在20实际90年代末期开发用来替代LDAPv2. LDAPv3 为LDAP增加了以下功能:
- 使用SASL实现强验证和数据安全服务
- 使用TLS (SSL)实现证书验证和数据安全服务
- 使用Unicode实现国际化
- 转发和配置
- 规划发现
- 扩展性 (控制, 扩展操作, 以及更多)
LDAPv2 过时了 (RFC3494). 大部分所谓LDAPv2实现(including slapd(8))已经不符合LDAPv2技术规范了, 那些声称支持LDAPv2的实现之间的互操作性是有限的. 由于LDAPv2和LDAPv3显著的差异, 同时部署LDAPv2和LDAPv3是很成问题的. 应该避免使用LDAPv2. LDAPv2缺省是被禁用的.
LDAP vs RDBMS
这个问题被提到很多次,以不同的形式. 最常见的是: 为什么OpenLDAP不放弃 Berkeley DB 而使用一个关系型数据库管理系统(RDBMS)替代它? 通常, 我们可以预期商业级RDBMS的复杂算法将使 OpenLDAP 更快或者反正是更好, 同时允许其他应用程序分享其数据.
简单的答案是,使用嵌入式数据库和定制的索引系统允许OpenLDAP提供更高的性能和可扩展性而又不减少可靠性. OpenLDAP使用Berkeley DB并行/事务数据库软件. 业界领先的商业目录软件也使用同样的软件.
现在来详细回答一下. 任何时候我们总是面对 RDBMSes vs. directories的选择. 很难选择,并且不存在简单的答案.
给目录一个关系数据库管理系统的后端来解决所有问题,这个想法无疑是很诱人的. 无论如何, 它是一头猪(译者:呃,老外骂人了). 这是因为数据模型是非常不同的. 用关系型数据库去表现目录数据,将需要把数据分割到多个表里面.
考虑一下关于 person 这个 objectclass. 它的定义需要属性类型 objectclass, sn 和 cn,并且允许属性类型 userPassword, telephoneNumber, seeAlso 以及 description. 所有这些属性都是多值的, 所以一个常规的需求就会把每个属性类型放大一个单独的表里面.
现在你不得不决定这些表的适当的键. 主键可能是一个DN的组合, 但是这在绝大多数数据库实现中是非常低效的.
现在的大问题是根据一个条目请求去不同的磁盘区域访问数据. 在某些应用里面这个还可以做到,但是在很多应用里面性能就很困难.
唯一可以放到主表条目里面的属性类型是那些强制性的和单值的. 你也可以增加可选性的单值属性并把他们设为NULL或其他什么东西.
但是请等一下, 这个条目有多个 objectclasses并且他们组织成一个继承的层次. 一个 objectclass organizationalPerson 的条目现在有从 person 来的属性加上一些其他的以及一些原有的可选的属性类型现在变成强制性的了.
怎么办? 我们应该用不同的表放不同的objectclasses吗? 这样 person 将有一个条目在 person 表, 另一个在 organizationalPerson表, 以此类推. 或我们应该不管 person 而把每样东西放在第二个表?
但是对于类似(cn=*) 这样的过滤器,cn是一个在很多很多objectclasses里出现的属性类型,我们怎么办? 我们应该为匹配那个过滤器搜索所有可能的表吗? 不是很有吸引力.
一旦达到这种程度, 三种办法浮现在脑海中。 一个是做全面正常化,以使每个属性类型,不管如何,都有自己单独的表。简单的方法DN作为主键的一部分是非常浪费的, 并且调用的是那个条目的唯一性的数字id而不是键,并且需要一个表来负责映射DN到id。这个方法, 无论如何, 当从一个或多个条目中请求很多属性类型的时候是非常低效的. 这样一个数据库, 尽管繁琐, 也可能由SQL应用程序管理.
第二个办法是把整个DN作为一个blob类型字段存在表里由所有条目共享,不管objectclass,并且额外的表作为第一个表的索引. 索引表不是数据库索引, 而是完全由LDAP服务端实现来管理. 无论如何, 无法利用SQL数据库了. 因此,一个完全成熟的数据库系统很少或根本没有优势. 全功能的通用数据库是不需要的. 更好的办法是使用一些轻型快速的, 如 Berkeley DB.
从一种完全不同的方式来看这件事,就是放弃任何实现目录数据模型的希望。在这种情况下, LDAP被用作一个对数据的访问协议,这些数据仅提供目录数据模型层面的数据. 例如,它可能是只读,或允许更新,适用限制,如单值属性类型允许多个值。或无法添加新的objectclasses到现有的条目或删除其中之一。限制范围的跨度从允许的限制(可能在其他地方造成的访问控制结果),到直接侵犯数据模型。无论如何,它是一个可行的办法,对之前就存在的用于其它应用程序的数据提供LDAP操作. 但是从概念上讲,我们并不真的拥有一个"目录".
现有的商业LDAP服务器采用关系数据库实现的,都是从第一种或第三种方法。我不知道任何使用关系数据库的实现如何低效地执行BDB做起来很高效的事情。 对那些对"第三种"方法感兴趣的人来说 (把现有的数据的数据库管理系统作为的LDAP树,比起典型的LDAP模式有一定的局限性,但有可能在LDAP和SQL应用之间实现互操作性):
OpenLDAP包含了 back-sql - 这个后端使得它(第三种方法)成为可能. 它使用 ODBC + 扩展来把LDAP查询翻译成你的RDBMS规划的SQL查询, 提供不同的级别的操作 - 从只读到全访问,取决于你使用的 RDBMS , 和你的规划.
更多关于概念和限制的信息, 见 slapd-sql(5) 手册页, 或 Backends 一节. 在 back-sql/rdbms_depend/* 子目录也有很多关于RDBMS的例子.
什么是slapd以及它能干什么?
slapd(8) 是一个 LDAP 目录服务期,可以运行在各种不同的平台之上. 你可使用它提供一个你自己的目录服务. 你的目录可能包含非常多期望放进去的东西. 你可以把它连接到全球 LDAP 目录服务中, 或完全自己运行一个目录服务. 一些 slapd's 更有意思的功能和能力包括:
LDAPv3: slapd实现了轻量级目录访问协议的版本3. slapd支持 LDAP 运行于 IPv4 和 IPv6 以及 Unix IPC.
简单验证和安全层: slapd通过使用SASL支持强验证和数据安全(完整性和保密性) 服务. slapd的SASL实现利用了 Cyrus SASL 软件,它支持不少机制,包括 DIGEST-MD5, EXTERNAL, 和 GSSAPI.
传输层安全: slapd通过使用TLS的(或SSL )支持基于证书的身份验证和数据安全(完整性和保密性)服务。slapd的TLS实现可以利用OpenSSL或GnuTLS软件。
拓扑控制: slapd可以被配置为根据网络的拓扑结构信息限制访问的套接字层。此功能利用了TCP包装。
访问控制: slapd提供了丰富和强大的访问控制设施,使您可以控制对你的数据库的信息的获取 。您可以基于LDAP授权信息, IP地址,域名和其他标准控制对条目的访问。slapd支持静态和动态的访问控制信息。slapd provides a rich and powerful access control facility,
国际化: slapd支持Unicode和语言标签。
可选的数据库后端: slapd配备了各种不同的数据库后端您可以从中选择。它们包括BDB,一个高性能的交易数据库后端;HDB,一个分级的高性能的交易后端;SHELL,一个后端接口通向任意 shell脚本;和PASSWD,一个简单的后端接口,到passwd ( 5 )文件。BDB和HDB后端利用了Oracle Berkeley DB。
多数据库实例: slapd可以配置为在同一时间服务多个数据库。这意味着,一个单一的slapd服务器能够使用相同或不同的数据库后端,响应许多逻辑上不同的LDAP树的请求。
通用模块API :如果您需要更加个性化, slapd让你轻松地写自己的模块。slapd包括两个不同的部分:处理和LDAP客户沟通协议的前端;和处理特定任务,如数据库操作的模块。因为这两个部分之间通过一个明确界定的C API通讯 ,你可以用多种方式写自己的定制模块扩展slapd。此外,提供了一些可编程数据库模块。这些允许你使用流行的编程语言( Perl,shell和SQL )暴露外部数据源给slapd 。
线程: slapd是线程高性能的。一个单一的多线程slapd进程使用线程池处理所有传入的请求。这减少了系统开销,同时提供所需的高性能。
复制: slapd可以被配置为维护目录信息的影子复制。这个单主/多从复制规划,对于安装单一的slapd而不提供必要的可用性和可靠性的高容量环境,是至关重要的。对于不能接受单点故障的要求极高的环境,也可以用多主复制。 slapd包含了对LDAP基于同步的复制的支持。
代理缓存: slapd可以被配置为一个缓存的LDAP代理服务。
配置: slapd是高度可配置的,通过一个单一的配置文件你可以改变一切,任何你想改变的东西。配置选项有合理的默认值,使您的工作更加容易。配置也可以使用LDAP本身动态的执行,这极大地改善了可管理性。
快速开始指南
以下是一个OpenLDAP2.4的快速开始指南, 包含独立的LDAP守护进程, slapd(8).
这表示带你走过安装和配置OpenLDAP软件所需要的基本步骤. 应该结合其它文档一起来看,包括本文的其他章节,手册页面,以及其随同软件提供的材料(例如INSTALL文档)或OpenLDAP网站(http://www.OpenLDAP.org),特别是OpenLDAP的常见问题解答(http://www.OpenLDAP.org/faq/?file=2)。
如果你打算严肃使用OpenLDAP软件, 你应该在尝试安装软件之前阅读本文的全文.
注意: 这个快速开始指南没有使用强验证或任何保密服务. 这些服务在本OpenLDAP管理员指南的其它章节里有所描述.
- 1. 获得软件
- 你可以跟着OpenLDAP软件下载页面 (http://www.openldap.org/software/download/) 的提示获得一份软件拷贝. 建议新用户使用最新版本.
- 2. 解包分发版
- 给源码选择一个目录, 进入到那个目录, 使用以下命令解包分发版:
gunzip -c openldap-VERSION.tgz | tar xvfB -
- 然后进入分发版的目录:
cd openldap-VERSION- 你要把VERSION换成相应的版本名.
- 3. 阅读文档
- 你现在应该阅读分发版所提供的COPYRIGHT, LICENSE, README 和 INSTALL 文档. COPYRIGHT 和 LICENSE 提供的信息是关于可接受的使用,拷贝方式和OpenLDAP软件的有限保证.
- 你也应该阅读本文的其他章节. 特别是, 本文的编译和安装OpenLDAP软件章节提供了依赖的软件的详细信息和安装过程.
- 4. 运行configure
- 你将需要运行提供的configure脚本来配置分发版使它能在你的系统上进行编译. configure脚本接受很多命令行选项以打开或关闭可选的软件功能. 通常缺省就差不多了, 但是你可以改变它们. 要获得configure可接受的选项的完整列表, 使用 --help 选项:
./configure --help
- 无论如何, 是你在使用这个指南, 我们假定你足够勇敢,就让configure决定什么是最好的:
./configure- 假定configure不喜欢你的系统, 你可以继续编译软件. 如果configure抱怨, 那么, 你可能需要去看看软件常见问题解答的安装一节 (http://www.openldap.org/faq/?file=8) 和/或仔细阅读本文的编译和安装OpenLDAP软件一章.
- 5. Build软件.
- 下一步是编译软件. 这一步分为两部分, 首先我们构建依赖,然后我们编译软件:
make depend make
- 两个 makes 都应该不出错地完成.
- 6. 测试build.
- 为了确保正确的编译, 你应该运行测试套件(只要花几分钟):
make test
- 应用你的配置的测试将运行并应该通过. 一些测试, 例如复制测试, 可以忽略.
- 7. 安装软件.
- 你现在准备安装软件; 这通常需要超级用户权限:
su root -c 'make install'
- 现在每样东西应该都被安装在 /usr/local 目录下(或任何configure指定的安装前缀).
- 8. 编辑配置文件.
- 使用你偏爱的编辑器编辑附带的slapd.conf(5)例子(通常安装在 /usr/local/etc/openldap/slapd.conf) 来包含一个如下格式的 BDB 数据库定义:
database bdb
suffix "dc=<MY-DOMAIN>,dc=<COM>"
rootdn "cn=Manager,dc=<MY-DOMAIN>,dc=<COM>"
rootpw secret
directory /usr/local/var/openldap-data- 确保以你的域名的适当部分替换<MY-DOMAIN>和<COM> . 例如, 对于 example.com, 使用:
database bdb
suffix "dc=example,dc=com"
rootdn "cn=Manager,dc=example,dc=com"
rootpw secret
directory /usr/local/var/openldap-data- 如果你的域包含额外的部分, 例如 eng.uni.edu.eu, 使用:
database bdb
suffix "dc=eng,dc=uni,dc=edu,dc=eu"
rootdn "cn=Manager,dc=eng,dc=uni,dc=edu,dc=eu"
rootpw secret
directory /usr/local/var/openldap-data- 关于配置slapd(8)的细节,可在slapd.conf(5) 手册页,以及本文的 slapd 配置文件 一章找到. 注意启动slapd(8)之前那些定义的目录必须实际存在.
- 9. 启动SLAPD.
- 现在你准备启动独立的LDAP守护进程, slapd(8), 运行这个命令:
su root -c /usr/local/libexec/slapd
- 为了检查服务器是否运行以及是否被正确地配置好, 你可以使用ldapsearch(1)针对它运行一个搜索. 缺省的, ldapsearch被安装在 /usr/local/bin/ldapsearch:
ldapsearch -x -b '' -s base '(objectclass=*)' namingContexts
- 注意在命令参数周围使用单引号来避免shell被特殊字符中断. 它应该返回:
dn:
namingContexts: dc=example,dc=com- 关于运行slapd(8)的细节可以在slapd(8)手册页以及本文的 运行slapd 一章找到.
- 10. 添加初始条目到目录中去.
- 你可以使用ldapadd(1)添加条目到你的LDAP目录. ldapadd期待的输入是LDIF格式. 我们将分两步走:
- 建立LDIF文件
- 运行ldapadd
- 使用你偏爱的编辑器新建一个LDIF文件,包含如下内容:
dn: dc=<MY-DOMAIN>,dc=<COM>
objectclass: dcObject
objectclass: organization
o: <MY ORGANIZATION>
dc: <MY-DOMAIN>
dn: cn=Manager,dc=<MY-DOMAIN>,dc=<COM>
objectclass: organizationalRole
cn: Manager- 确保使用你的域名的适当部分替换<MY-DOMAIN>和<COM>. <MY ORGANIZATION>应该被你的机构名称替换掉. 当你剪切粘贴时, 确定本例中的每一行的前面和后面都没有空格.
dn: dc=example,dc=com
objectclass: dcObject
objectclass: organization
o: Example Company
dc: example
dn: cn=Manager,dc=example,dc=com
objectclass: organizationalRole
cn: Manager- 现在, 你可以运行ldapadd(1)来添加这些条目到你的目录.
ldapadd -x -D "cn=Manager,dc=<MY-DOMAIN>,dc=<COM>" -W -f example.ldif
- 确保用你的域名的适当部分替换<MY-DOMAIN>和<COM>. 你将收到提示输入密码,也就是在slapd.conf中定义的"secret". 例如, 对于 example.com, 使用:
ldapadd -x -D "cn=Manager,dc=example,dc=com" -W -f example.ldif
- 这里example.ldif就是你上面新建的文件.
- 另外关于建立目录的信息可以在本文的 数据库建立和维护工具 一章找到.
- 11. 看它是否起作用.
- 现在我们准备检验目录中添加的条目. 你可使用任何LDAP客户端来做这件事, 但我们的例子使用ldapsearch(1)工具. 记住把 dc=example,dc=com 替换成你的网站的正确的值:
ldapsearch -x -b 'dc=example,dc=com' '(objectclass=*)'
- 本命令将搜索和接收这个数据库中的每一个条目.
现在你准备使用ldapadd(1)或其它LDAP客户端添加更多的条目, 试验更多的配置选项, 后端安排, 等等.
注意缺省的情况下, slapd(8)数据库赋予阅读权限给每个人,除了超级用户(即配置文件中的rootdn参数). 强烈建议你建立控制来限制授权用户的操作. 操作权限控制在 访问控制 章讨论. 也鼓励你阅读安全事项,使用SASL和使用TLS章节.
接下来的章节提供更多编译,安装和运行slapd(8)的详细信息.
大图片-配置选择
本节概述了各种LDAP目录配置,以及如何使您的独立的LDAP守护进程slapd ( 8 )适合世界其他国家。
本地目录服务
在这种配置中,您运行slapd ( 8 )实例,只为您的本地网域提供目录服务。它不以任何方式与其他目录服务器交互。这种配置如图3.1.

图 3.1: 本地服务配置.
如果您刚刚起步(快速启动指南的目的之一就是为了你这种人),或者如果你想提供本地服务且对连接到世界其他地区不感兴趣,请使用此配置。如果以后你想的话,这也很容易升级到另一个配置。
带转发的本地服务
在这种配置中,您运行slapd ( 8 )实例,为您的本地网域提供目录服务,并配置它返回转发到其他能够处理请求的服务器。您可以自己运行此服务(或多个服务)或使用别人提供给您的服务。这种配置如图3.2.
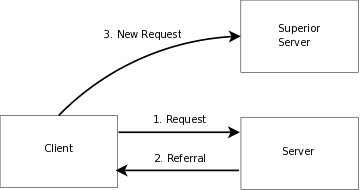
图 3.2: 带转发的本地服务
如果你想提供本地服务,并参与全球目录,或者您想代表负责下属条目到另一台服务器,使用此配置。
可复制的目录服务
slapd ( 8 )包括了对LDAP基于同步的复制的支持, 即所谓syncrepl ,可用于在多个目录服务器上维持目录信息的影子复制。在其最基本的配置,主服务器是一个syncrepl供应商,而一个或多个从服务器(或影子服务器)是syncrepl消费者。一个主从配置的例子如图3.3. 多主机的配置,也支持。
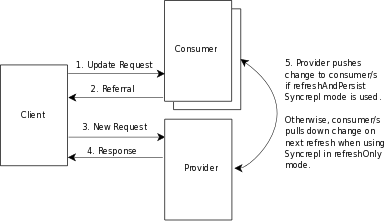
图 3.3: 可复制的目录服务
此配置可用于头两个配置的任何一个情况下,例如一个单一的slapd ( 8 )没有提供所需的可靠性和可用性。
分布式本地目录服务
在这种配置中,当地的服务被分割成较小的服务,每个都是可复制的,和上下级粘在一起转发。
编译和安装OpenLDAP软件
这一章详细说明如何编译和安装包含了slapd ( 8 ) ,独立的LDAP守护进程的OpenLDAP软件包。编译和安装OpenLDAP软件需要几个步骤:安装依赖的软件,配置OpenLDAP软件本身,编译,并最终安装。以下各节详细描述了此过程中。
获得和解包软件
您可以从该项目的下载页面上http://www.openldap.org/software/download/或直接从该项目的FTP服务在ftp://ftp.openldap.org/pub/OpenLDAP/获取OpenLDAP软件 。
该项目提供两个系列的包作为一般用途。该项目发布版本提供新的特性和错误修正。虽然该项目采取措施,以改善这些版本的稳定性,但是经常会版本发布之后才发现问题。稳定版本是最新的经过一般性的使用已经显示出稳定的版本。
OpenLDAP软件的用户可以选择最适当的一系列安装,这取决于他们对于最新功能与稳定表现的期望。
OpenLDAP软件下载后,你需要从压缩存档文件提取发布版并更改您的工作目录到发布版的根目录:
gunzip -c openldap-VERSION.tgz | tar xf - cd openldap-VERSION
你需要把 VERSION 换成发布版的实际版本号.
您现在应该阅读版权,许可证,自述文件和发布版提供的安装文件规定。版权和许可提供对OpenLDAP软件的可接受的使用,复制,和限制的保证。自述文件和安装文件提供依赖的软件和安装过程的详细资料。
依赖的软件
OpenLDAP软件依靠一些第三方分发的软件包。根据您打算使用的不同的功能,您可能必须下载并安装一些额外的软件包。本节详述通常需要的您可能需要安装的第三方软件的软件包。然而,一个最新的依赖软件信息,应在自述文件中获得。请注意,其中一些第三方软件包可能依赖于额外的软件包。每个软件包提供了它自己的安装说明。
传输层安全
OpenLDAP客户端和服务器需要安装OpenSSL或GnuTLS的TLS库来提供TLS,传输层安全服务。虽然一些操作系统可能提供这些库的一部分,作为基本系统或一个可选的软件组件, OpenSSL和GnuTLS往往需要单独安装。
OpenSSL可从 http://www.openssl.org/ 获得. GnuTLS 可从 http://www.gnu.org/software/gnutls/ 获得.
OpenLDAP 软件将不是完全兼容 LDAPv3,除非 OpenLDAP 的配置检测到一个可用的 TLS 库.
简单验证和安全层
OpenLDAP客户端和服务器需要安装 Cyrus SASL 库提供简单身份认证和安全层服务。虽然一些操作系统可能会提供这个库,作为基本系统的一部分或作为一个可选的软件组件,Cyrus SASL 往往需要单独安装。
Cyrus SASL 可从 http://asg.web.cmu.edu/sasl/sasl-library.html 获得. Cyrus SASL 将使用 OpenSSL 和 Kerberos/GSSAPI 库,如果预先安装了的话.
OpenLDAP软件将不完全兼容 LDAPv3,除非 OpenLDAP 的配置检测到一个可用的 Cyrus SASL 安装.
Kerberos验证服务
OpenLDAP客户端和服务器支持Kerberos身份验证服务。特别是, OpenLDAP支持 Kerberos V GSS-API SASL 认证机制,称为GSSAPI机制。此功能要求,除了Cyrus SASL 库之外,还要有 Heimdal 或 MIT Kerberos V 库。
Heimdal Kerberos 可从 http://www.pdc.kth.se/heimdal/ 获得. MIT Kerberos 可从 http://web.mit.edu/kerberos/www/ 获得.
强烈推荐使用强验证服务, 例如 Kerberos 提供的那些.
数据库软件
OpenLDAP的slapd ( 8 )的BDB和HDB主要数据库后端需要甲骨文公司的Berkeley DB。如果在设定的时间没有可用的,您将无法与这些主要的数据库后端编译slapd ( 8 )。
您的操作系统可能提供一个支持版本的Berkeley DB作为基础系统或作为一个可选的软件组件。如果不是这样,您将不得不自己去获取并安装它。
Berkeley DB 可从 Oracle 公司的 Berkeley DB 下载页 http://www.oracle.com/technology/software/products/berkeley-db/index.html 获得.
有很多可用的版本. 通常, 推荐最近的版本 (包含发布的补丁) . 如果你想使用BDB或HDB数据库后端,这个包是必需的.
注意: 请看推荐的 OpenLDAP 软件依赖版本 一节获得更多信息.
线程
OpenLDAP设计成充分利用线程。 OpenLDAP支持POSIX pthreads,Mach CThreads ,以及其他一些品种。如果不能找到一个合适的线程子系统,configure会抱怨。如果发生这种情况,请咨询OpenLDAP常见问题 http://www.openldap.org/faq/ 中的 软件|安装|平台 提示部分 。
TCP包装
slapd(8) 支持 TCP 包装 (IP 级访问控制过滤), 如果预先安装了的话. 建议为包含非公开信息的服务器使用 TCP 包装或其他 IP级的访问过滤 (例如那些IP级防火墙所提供的).
运行configure
现在,您或许应该运行configure脚本的 --help 选项。这将给你一个选项列表,编译OpenLDAP时您可以变更这些选项 。使用此方法可以启用或禁用OpenLDAP的许多功能。
./configure --help
configure脚本还将研究各种环境变量的某些设置。这些环境变量包括:
表 4.1: 环境标量
| 变量 | 描述 |
|---|---|
| CC | 指定替代的 C 编译器 |
| CFLAGS | 指定额外的编译器 flags |
| CPPFLAGS | 指定 C 预编译器 flags |
| LDFLAGS | 指定 linker flags |
| LIBS | 指定额外的库 |
现在以任何期望的配置选项或环境变量运行configure脚本.
[[env] settings] ./configure [options]
作为一个例子,假设我们要安装OpenLDAP,后端是BDB并支持TCP封装。默认情况下,BDB是启用的而TCP封装并非如此。所以,我们只需要指定 --with-wrappers, 来包含对TCP封装的支持:
./configure --with-wrappers
无论如何,这无法定位没有安装到系统目录的依赖的软件. 例如, 如果 TCP Wrappers 头文件和库文件分别被安装在 /usr/local/include 和 /usr/local/lib, configure 脚本应该如下调用:
env CPPFLAGS="-I/usr/local/include" LDFLAGS="-L/usr/local/lib" \ ./configure --with-wrappers
注意: 一些 shells, 例如那些衍生自Bourne sh(1)的 shell, 不需要使用 env(1) 命令. 在某些情况下, 环境变量不得不使用替代的语法来指定.
configure脚本通常将自动检测适当的设定. 如果你对此阶段有任何问题, 咨询任何平台特定的提示并检查你的configure选项, 如果有的话.
编译软件
一旦你运行了 configure 脚本,输出的最后一行应该是:
Please "make depend" to build dependencies如果最后一行输出不符, configure失败了, 你需要阅读它的输出来决定什么地方出错了. 你不应继续下去,直到configure成功的完成.
编译依赖, 运行:
make depend现在编译软件, 这一步将确实地编译OpenLDAP.
make你应该仔细检查这个命令的输出信息以确认每件东西正确地被编译了. 注意这个命令同时编译了 LDAP 库文件和相关的客户端以及 slapd(8).
测试软件
一旦软件被正确地配置和成功地编译了, 你应该运行测试套件来检查这个版本.
make test
适用于您的配置地试验将运行,它们应该通过。一些测试,如复制测试,可以跳过,如果您的配置不支持的话。
安装软件
一旦你成功地测试了软件, 你开始准备安装它. 你将需要在运行configure时你指定的那些安装目录的写权限. 缺省OpenLDAP软件安装在/usr/local. 如果你用 --prefix configure 选项改变了设置 , 它将被安装在你提出的位置.
典型的, 安装需要超级用户权限. 从OpenLDAP源码根目录, 键入:
su root -c 'make install'
需要的时候输入适当的密码.
你应该仔细检查此命令的输出以确保每件东西正确地安装了. 缺省你将在 /usr/local/etc/openldap 发现slapd(8)的配置文件. 更多信息见 配置 slapd 一章.
配置slapd
一旦该软件已编译并安装后,您准备配置slapd ( 8 ) ,用于您的网站。与以前OpenLDAP的版本不同,slapd ( 8 )运行时配置在2.3 (及更高版本)是完全的允许LDAP并且可以LDIF数据使用标准的LDAP操作来管理 。LDAP配置引擎允许所有slapd的配置选项在运行中改变,一般不需要重新启动服务器以使更改生效。旧风格slapd.conf ( 5 )文件仍然是支持的,但必须转换为新的slapd配置( 5 )格式,允许运行时改变被保存。虽然旧的风格配置使用一个单一的文件,通常安装在/usr/local/etc/openldap/slapd.conf ,新的风格采用了slapd后端数据库来存储配置。配置数据库通常放在/usr/local/etc/openldap/slapd.d目录。从slapd.conf格式转换成slapd.d格式时,任何包含文件也将被集成到由此产生的配置数据库。
可以通过slapd ( 8 )的命令行选项指定候补的配置目录(或文件) 。本章说明配置系统的一般格式,然后详细说明了常用的配置设置。
注:一些后端和分布式覆盖还不支持运行时配置。在这种情况下,旧式slapd.conf ( 5 )文件必须使用。
配置布局
slapd配置作为一个特殊的拥有预定义的规划和DIT的LDAP目录来存储。有一些特定的objectClasses用于进行全球配置选项,架构定义,后端和数据库的定义,以及各种其他项目。样本配置树如图5.1.
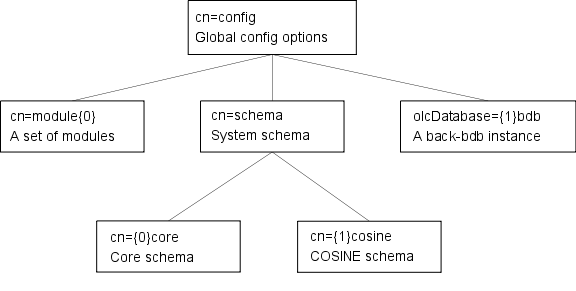
图 5.1: 样本配置树.
其他对象可能是配置的一部分,但省略了明确的说明.
该slapd配置配置树有一个非常特殊的结构。树的根被命名为 cn=config,并且包含全球配置设置。其他设置均包含在独立的子条目中::
- 动态装载模块
- 这些可能只在使用了 --enable-modules 选项 configure 软件的时候需要用.
- 规划定义
- cn=schema,cn=config 条目包含了系统的规划(在slapd中所有规划都是硬编码).
- cn=schema,cn=config 的子条目包含从配置文件装载或运行时添加的的用户规划.
- 特定后端配置
- 特定数据库配置
- Overlay被定义在数据库条目的子条目下.
- 数据库和Overlay也可以有其他的杂项子条目.
LDIF文件的通常规则适用于配置信息:以'#'字符开始的注释行会被忽略。如果一行的开始是一个空格,它被认为是延续前行(即使前行是注释)并且这个单个的空格会被删除。条目是由空白行分开的。
config LDIF的总体布局如下:
# 全球配置设定
dn: cn=config
objectClass: olcGlobal
cn: config
<global config settings>
# 规划定义
dn: cn=schema,cn=config
objectClass: olcSchemaConfig
cn: schema
<system schema>
dn: cn={X}core,cn=schema,cn=config
objectClass: olcSchemaConfig
cn: {X}core
<core schema>
# 额外的用户定义的规划
...
# 后端定义
dn: olcBackend=<typeA>,cn=config
objectClass: olcBackendConfig
olcBackend: <typeA>
<backend-specific settings>
# 数据库定义
dn: olcDatabase={X}<typeA>,cn=config
objectClass: olcDatabaseConfig
olcDatabase: {X}<typeA>
<database-specific settings>
# 随后的定义和设置
...一些以上所列项目在他们的名字有一个数字索引"{X}"。虽然大多数配置设置具有内在的次序依赖(即一个设置必须在另一个设定之前生效),LDAP数据库本身是无次序的。这个数字索引是用来在配置数据库强制一致性的次序,以便使所有的次序依赖被保存。在大多数情况下,并没有提供索引,它将根据条目创建的顺序自动生成。
配置指令被定义为一个独立属性的值。大部分用于slapd配置的属性和objectClasses在他们的名字有一个“olc”前缀 ( OpenLDAP配置)。通常在属性和旧式slapd.conf配置关键字之间有一对一的对应关系,使用关键字作为属性名称,以“olc”作前缀。
一个配置指令可采用参数。如果是这样,参数们由空格分开。如果参数包含空格,这个参数应包含在双引号里“像这样” 。在以下描述中,在方括号<>中的参数应被实际的文字替换 。
发布版包含一个配置文件例子,将被安装在/usr/local/etc/OpenLDAP目录。在/usr/local/etc/openldap/schema目录还提供了一些包含架构定义(属性类型和对象类)的文件。
配置指令
本节详述常用的配置指令。如需完整清单,请参阅slapd-config( 5 )帮助页面。本节将按自上而下的顺序排列配置指令,首先是全球性指令的 cn=config 项。每个指令将描述其默认值(如果有的话)和它的一个使用例子。
cn=config
此项目中所载的指令一般适用于把服务器作为一个整体。他们中的大多数是系统或面向连接的,而不是数据库相关的。此项目必须有olcGlobal对象。
olcIdleTimeout: <integer>
指定强行关闭闲置客户端连接等待的秒数。默认情况下,值为0,禁用此功能。
olcLogLevel: <level>
该指令规定在哪一级的调试和运行统计报表应syslogged (目前记录到syslogd ( 8 ) LOG_LOCAL4设施)。您必须配置OpenLDAP -enable-debug(默认)为工作(除了这两个统计级别,是始终启用的)。日志级别可能会被指定为整数或关键字。可使用多重记录级别并且级别是可添加的。要显示哪些层次对应于什么样的调试,以 -D? 调用 slapd 或参考下表。<level>可能的值有:
表 5.1: 调试级别
| 级别 | 关键字 | 描述 |
|---|---|---|
| 0 | 不调试 | |
| 1 | (0x1 trace) | 跟踪函数调用 |
| 2 | (0x2 packets) | 调试包的处理 |
| 4 | (0x4 args) | 重度跟踪调试 |
| 8 | (0x8 conns) | 连接管理 |
| 16 | (0x10 BER) | 打印发送和接收的包 |
| 32 | (0x20 filter) | 搜索过滤器的处理 |
| 64 | (0x40 config) | 配置处理 |
| 128 | (0x80 ACL) | 访问控制列表处理 |
| 256 | (0x100 stats) | 连接/操作/结果的统计日志 |
| 512 | (0x200 stats2) | 发送的条目的统计日志 |
| 1024 | (0x400 shell) | 打印和shell后端的通信 |
| 2048 | (0x800 parse) | 打印条目解析调试 |
| 16384 | (0x4000 sync) | syncrepl消费者处理 |
| 32768 | (0x8000 none) | 只显示那些不受日志级别设置影响的消息 |
预期的日志级别可作为一个单一的整数输入,它结合了 (或运算) 预期级别(们), 包括十进制或十六进制符号, 作为一些整数的列表 (内部或运算), 或作为名字的列表,展示在括号里, 例如
olcLogLevel 129
olcLogLevel 0x81
olcLogLevel 128 1
olcLogLevel 0x80 0x1
olcLogLevel acl trace是等效的.
例子:
olcLogLevel -1
This will cause lots and lots of debugging information to be logged.
olcLogLevel conns filter
Just log the connection and search filter processing.
olcLogLevel none
Log those messages that are logged regardless of the configured loglevel. This differs from setting the log level to 0, when no logging occurs. At least the None level is required to have high priority messages logged.
Default:
olcLogLevel stats
Basic stats logging is configured by default. However, if no olcLogLevel is defined, no logging occurs (equivalent to a 0 level).
olcReferral <URI>
This directive specifies the referral to pass back when slapd cannot find a local database to handle a request.
Example:
olcReferral: ldap://root.openldap.org
This will refer non-local queries to the global root LDAP server at the OpenLDAP Project. Smart LDAP clients can re-ask their query at that server, but note that most of these clients are only going to know how to handle simple LDAP URLs that contain a host part and optionally a distinguished name part.
示例条目
dn: cn=config objectClass: olcGlobal cn: config olcIdleTimeout: 30 olcLogLevel: Stats olcReferral: ldap://root.openldap.org
cn=module
If support for dynamically loaded modules was enabled when configuring slapd, cn=module entries may be used to specify sets of modules to load. Module entries must have the olcModuleList objectClass.
olcModuleLoad: <filename>
Specify the name of a dynamically loadable module to load. The filename may be an absolute path name or a simple filename. Non-absolute names are searched for in the directories specified by the olcModulePath directive.
olcModulePath: <pathspec>
Specify a list of directories to search for loadable modules. Typically the path is colon-separated but this depends on the operating system.
示例条目
dn: cn=module{0},cn=config objectClass: olcModuleList cn: module{0} olcModuleLoad: /usr/local/lib/smbk5pwd.la
dn: cn=module{1},cn=config objectClass: olcModuleList cn: module{1} olcModulePath: /usr/local/lib:/usr/local/lib/slapd olcModuleLoad: accesslog.la olcModuleLoad: pcache.la
cn=schema
The cn=schema entry holds all of the schema definitions that are hard-coded in slapd. As such, the values in this entry are generated by slapd so no schema values need to be provided in the config file. The entry must still be defined though, to serve as a base for the user-defined schema to add in underneath. Schema entries must have the olcSchemaConfig objectClass.
olcAttributeTypes: <RFC4512 Attribute Type Description>
This directive defines an attribute type. Please see the Schema Specification chapter for information regarding how to use this directive.
olcObjectClasses: <RFC4512 Object Class Description>
This directive defines an object class. Please see the Schema Specification chapter for information regarding how to use this directive.
示例条目
dn: cn=schema,cn=config objectClass: olcSchemaConfig cn: schema
dn: cn=test,cn=schema,cn=config objectClass: olcSchemaConfig cn: test olcAttributeTypes: ( 1.1.1
NAME 'testAttr' EQUALITY integerMatch SYNTAX 1.3.6.1.4.1.1466.115.121.1.27 )
olcAttributeTypes: ( 1.1.2 NAME 'testTwo' EQUALITY caseIgnoreMatch
SUBSTR caseIgnoreSubstringsMatch SYNTAX 1.3.6.1.4.1.1466.115.121.1.44 )
olcObjectClasses: ( 1.1.3 NAME 'testObject'
MAY ( testAttr $ testTwo ) AUXILIARY )
具体后端指令
Backend directives apply to all database instances of the same type and, depending on the directive, may be overridden by database directives. Backend entries must have the olcBackendConfig objectClass.
olcBackend: <type>
This directive names a backend-specific configuration entry. <type> should be one of the supported backend types listed in Table 5.2. Table 5.2: Database Backends Types Description bdb Berkeley DB transactional backend config Slapd configuration backend dnssrv DNS SRV backend hdb Hierarchical variant of bdb backend ldap Lightweight Directory Access Protocol (Proxy) backend ldif Lightweight Data Interchange Format backend meta Meta Directory backend monitor Monitor backend passwd Provides read-only access to passwd(5) perl Perl Programmable backend shell Shell (extern program) backend sql SQL Programmable backend
Example:
olcBackend: bdb
There are no other directives defined for this entry. Specific backend types may define additional attributes for their particular use but so far none have ever been defined. As such, these directives usually do not appear in any actual configurations.
示例条目
dn: olcBackend=bdb,cn=config objectClass: olcBackendConfig olcBackend: bdb
特定数据库
Directives in this section are supported by every type of database. Database entries must have the olcDatabaseConfig objectClass.
olcDatabase: [{<index>}]<type>
This directive names a specific database instance. The numeric {<index>} may be provided to distinguish multiple databases of the same type. Usually the index can be omitted, and slapd will generate it automatically. <type> should be one of the supported backend types listed in Table 5.2 or the frontend type.
The frontend is a special database that is used to hold database-level options that should be applied to all the other databases. Subsequent database definitions may also override some frontend settings.
The config database is also special; both the config and the frontend databases are always created implicitly even if they are not explicitly configured, and they are created before any other databases.
Example:
olcDatabase: bdb
This marks the beginning of a new BDB database instance.
olcAccess: to <what> [ by <who> [<accesslevel>] [<control>] ]+
This directive grants access (specified by <accesslevel>) to a set of entries and/or attributes (specified by <what>) by one or more requestors (specified by <who>). See the Access Control section of this guide for basic usage.
Note: If no olcAccess directives are specified, the default access control policy, to * by * read, allows all users (both authenticated and anonymous) read access.
Note: Access controls defined in the frontend are appended to all other databases' controls.
olcReadonly { TRUE | FALSE }
This directive puts the database into "read-only" mode. Any attempts to modify the database will return an "unwilling to perform" error.
Default:
olcReadonly: FALSE
olcRootDN: <DN>
This directive specifies the DN that is not subject to access control or administrative limit restrictions for operations on this database. The DN need not refer to an entry in this database or even in the directory. The DN may refer to a SASL identity.
Entry-based Example:
olcRootDN: "cn=Manager,dc=example,dc=com"
SASL-based Example:
olcRootDN: "uid=root,cn=example.com,cn=digest-md5,cn=auth"
See the SASL Authentication section for information on SASL authentication identities.
olcRootPW: <password>
This directive can be used to specify a password for the DN for the rootdn (when the rootdn is set to a DN within the database).
Example:
olcRootPW: secret
It is also permissible to provide a hash of the password in RFC2307 form. slappasswd(8) may be used to generate the password hash.
Example:
olcRootPW: {SSHA}ZKKuqbEKJfKSXhUbHG3fG8MDn9j1v4QN
The hash was generated using the command slappasswd -s secret.
olcSizeLimit: <integer>
This directive specifies the maximum number of entries to return from a search operation.
Default:
olcSizeLimit: 500
See the Limits section of this guide and slapd-config(5) for more details.
olcSuffix: <dn suffix>
This directive specifies the DN suffix of queries that will be passed to this backend database. Multiple suffix lines can be given, and usually at least one is required for each database definition. (Some backend types, such as frontend and monitor use a hard-coded suffix which may not be overridden in the configuration.)
Example:
olcSuffix: "dc=example,dc=com"
Queries with a DN ending in "dc=example,dc=com" will be passed to this backend.
Note: When the backend to pass a query to is selected, slapd looks at the suffix value(s) in each database definition in the order in which they were configured. Thus, if one database suffix is a prefix of another, it must appear after it in the configuration.
olcSyncrepl
olcSyncrepl: rid=<replica ID> provider=ldap[s]://<hostname>[:port] [type=refreshOnly|refreshAndPersist] [interval=dd:hh:mm:ss] [retry=[<retry interval> <# of retries>]+] searchbase=<base DN> [filter=<filter str>] [scope=sub|one|base] [attrs=<attr list>] [attrsonly] [sizelimit=<limit>] [timelimit=<limit>] [schemachecking=on|off] [bindmethod=simple|sasl] [binddn=<DN>] [saslmech=<mech>] [authcid=<identity>] [authzid=<identity>] [credentials=<passwd>] [realm=<realm>] [secprops=<properties>] [starttls=yes|critical] [tls_cert=<file>] [tls_key=<file>] [tls_cacert=<file>] [tls_cacertdir=<path>] [tls_reqcert=never|allow|try|demand] [tls_ciphersuite=<ciphers>] [tls_crlcheck=none|peer|all] [logbase=<base DN>] [logfilter=<filter str>] [syncdata=default|accesslog|changelog]
这个指令定义当前数据库作为一个主服务器内容的复制,通过当前的slapd(8) 建立一个运行syncrepl复制引擎的复制消费者站点. 主数据库由provider参数定位于复制提供者站点. 复制数据库使用LDAP内容同步协议保持对主服务器内容的更新. 关于协议的更多信息参见 RFC4533.
The rid parameter is used for identification of the current syncrepl directive within the replication consumer server, where <replica ID> uniquely identifies the syncrepl specification described by the current syncrepl directive. <replica ID> is non-negative and is no more than three decimal digits in length.
The provider parameter specifies the replication provider site containing the master content as an LDAP URI. The provider parameter specifies a scheme, a host and optionally a port where the provider slapd instance can be found. Either a domain name or IP address may be used for <hostname>. Examples are ldap://provider.example.com:389 or ldaps://192.168.1.1:636. If <port> is not given, the standard LDAP port number (389 or 636) is used. Note that the syncrepl uses a consumer-initiated protocol, and hence its specification is located at the consumer site, whereas the replica specification is located at the provider site. syncrepl and replica directives define two independent replication mechanisms. They do not represent the replication peers of each other.
The content of the syncrepl replica is defined using a search specification as its result set. The consumer slapd will send search requests to the provider slapd according to the search specification. The search specification includes searchbase, scope, filter, attrs, attrsonly, sizelimit, and timelimit parameters as in the normal search specification. The searchbase parameter has no default value and must always be specified. The scope defaults to sub, the filter defaults to (objectclass=*), attrs defaults to "*,+" to replicate all user and operational attributes, and attrsonly is unset by default. Both sizelimit and timelimit default to "unlimited", and only positive integers or "unlimited" may be specified.
The LDAP Content Synchronization protocol has two operation types: refreshOnly and refreshAndPersist. The operation type is specified by the type parameter. In the refreshOnly operation, the next synchronization search operation is periodically rescheduled at an interval time after each synchronization operation finishes. The interval is specified by the interval parameter. It is set to one day by default. In the refreshAndPersist operation, a synchronization search remains persistent in the provider slapd instance. Further updates to the master replica will generate searchResultEntry to the consumer slapd as the search responses to the persistent synchronization search.
If an error occurs during replication, the consumer will attempt to reconnect according to the retry parameter which is a list of the <retry interval> and <# of retries> pairs. For example, retry="60 10 300 3" lets the consumer retry every 60 seconds for the first 10 times and then retry every 300 seconds for the next three times before stop retrying. + in <# of retries> means indefinite number of retries until success.
The schema checking can be enforced at the LDAP Sync consumer site by turning on the schemachecking parameter. If it is turned on, every replicated entry will be checked for its schema as the entry is stored into the replica content. Every entry in the replica should contain those attributes required by the schema definition. If it is turned off, entries will be stored without checking schema conformance. The default is off.
The binddn parameter gives the DN to bind as for the syncrepl searches to the provider slapd. It should be a DN which has read access to the replication content in the master database.
The bindmethod is simple or sasl, depending on whether simple password-based authentication or SASL authentication is to be used when connecting to the provider slapd instance.
Simple authentication should not be used unless adequate data integrity and confidentiality protections are in place (e.g. TLS or IPsec). Simple authentication requires specification of binddn and credentials parameters.
SASL authentication is generally recommended. SASL authentication requires specification of a mechanism using the saslmech parameter. Depending on the mechanism, an authentication identity and/or credentials can be specified using authcid and credentials, respectively. The authzid parameter may be used to specify an authorization identity.
The realm parameter specifies a realm which a certain mechanisms authenticate the identity within. The secprops parameter specifies Cyrus SASL security properties.
The starttls parameter specifies use of the StartTLS extended operation to establish a TLS session before authenticating to the provider. If the critical argument is supplied, the session will be aborted if the StartTLS request fails. Otherwise the syncrepl session continues without TLS. Note that the main slapd TLS settings are not used by the syncrepl engine; by default the TLS parameters from a ldap.conf(5) configuration file will be used. TLS settings may be specified here, in which case any ldap.conf(5) settings will be completely ignored.
Rather than replicating whole entries, the consumer can query logs of data modifications. This mode of operation is referred to as delta syncrepl. In addition to the above parameters, the logbase and logfilter parameters must be set appropriately for the log that will be used. The syncdata parameter must be set to either "accesslog" if the log conforms to the slapo-accesslog(5) log format, or "changelog" if the log conforms to the obsolete changelog format. If the syncdata parameter is omitted or set to "default" then the log parameters are ignored.
The syncrepl replication mechanism is supported by the bdb and hdb backends.
See the LDAP Sync Replication chapter of this guide for more information on how to use this directive.
olcTimeLimit: <integer>
This directive specifies the maximum number of seconds (in real time) slapd will spend answering a search request. If a request is not finished in this time, a result indicating an exceeded timelimit will be returned.
Default:
olcTimeLimit: 3600
See the Limits section of this guide and slapd-config(5) for more details.
olcUpdateref: <URL>
This directive is only applicable in a slave slapd. It specifies the URL to return to clients which submit update requests upon the replica. If specified multiple times, each URL is provided.
Example:
olcUpdateref: ldap://master.example.net
Sample Entries
dn: olcDatabase=frontend,cn=config objectClass: olcDatabaseConfig objectClass: olcFrontendConfig olcDatabase: frontend olcReadOnly: FALSE
dn: olcDatabase=config,cn=config objectClass: olcDatabaseConfig olcDatabase: config olcRootDN: cn=Manager,dc=example,dc=com
BDB和HDB数据库指令
Directives in this category apply to both the BDB and the HDB database. They are used in an olcDatabase entry in addition to the generic database directives defined above. For a complete reference of BDB/HDB configuration directives, see slapd-bdb(5). In addition to the olcDatabaseConfig objectClass, BDB and HDB database entries must have the olcBdbConfig and olcHdbConfig objectClass, respectively.
olcDbDirectory: <directory>
This directive specifies the directory where the BDB files containing the database and associated indices live.
Default:
olcDbDirectory: /usr/local/var/openldap-data
olcDbCachesize: <integer>
This directive specifies the size in entries of the in-memory cache maintained by the BDB backend database instance.
Default:
olcDbCachesize: 1000
olcDbCheckpoint: <kbyte> <min>
This directive specifies how often to checkpoint the BDB transaction log. A checkpoint operation flushes the database buffers to disk and writes a checkpoint record in the log. The checkpoint will occur if either <kbyte> data has been written or <min> minutes have passed since the last checkpoint. Both arguments default to zero, in which case they are ignored. When the <min> argument is non-zero, an internal task will run every <min> minutes to perform the checkpoint. See the Berkeley DB reference guide for more details.
Example:
olcDbCheckpoint: 1024 10
olcDbConfig: <DB_CONFIG setting>
This attribute specifies a configuration directive to be placed in the DB_CONFIG file of the database directory. At server startup time, if no such file exists yet, the DB_CONFIG file will be created and the settings in this attribute will be written to it. If the file exists, its contents will be read and displayed in this attribute. The attribute is multi-valued, to accommodate multiple configuration directives. No default is provided, but it is essential to use proper settings here to get the best server performance.
Any changes made to this attribute will be written to the DB_CONFIG file and will cause the database environment to be reset so the changes can take immediate effect. If the environment cache is large and has not been recently checkpointed, this reset operation may take a long time. It may be advisable to manually perform a single checkpoint using the Berkeley DB db_checkpoint utility before using LDAP Modify to change this attribute.
Example:
olcDbConfig: set_cachesize 0 10485760 0
olcDbConfig: set_lg_bsize 2097512
olcDbConfig: set_lg_dir /var/tmp/bdb-log
olcDbConfig: set_flags DB_LOG_AUTOREMOVE
In this example, the BDB cache is set to 10MB, the BDB transaction log buffer size is set to 2MB, and the transaction log files are to be stored in the /var/tmp/bdb-log directory. Also a flag is set to tell BDB to delete transaction log files as soon as their contents have been checkpointed and they are no longer needed. Without this setting the transaction log files will continue to accumulate until some other cleanup procedure removes them. See the Berkeley DB documentation for the db_archive command for details. For a complete list of Berkeley DB flags please see - http://www.oracle.com/technology/documentation/berkeley-db/db/api_c/env_set_flags.html
Ideally the BDB cache must be at least as large as the working set of the database, the log buffer size should be large enough to accommodate most transactions without overflowing, and the log directory must be on a separate physical disk from the main database files. And both the database directory and the log directory should be separate from disks used for regular system activities such as the root, boot, or swap filesystems. See the FAQ-o-Matic and the Berkeley DB documentation for more details.
olcDbNosync: { TRUE | FALSE }
This option causes on-disk database contents to not be immediately synchronized with in memory changes upon change. Setting this option to TRUE may improve performance at the expense of data integrity. This directive has the same effect as using
olcDbConfig: set_flags DB_TXN_NOSYNC
olcDbIDLcacheSize: <integer>
Specify the size of the in-memory index cache, in index slots. The default is zero. A larger value will speed up frequent searches of indexed entries. The optimal size will depend on the data and search characteristics of the database, but using a number three times the entry cache size is a good starting point.
Example:
olcDbIDLcacheSize: 3000
olcDbIndex: {<attrlist> | default} [pres,eq,approx,sub,none]
This directive specifies the indices to maintain for the given attribute. If only an <attrlist> is given, the default indices are maintained. The index keywords correspond to the common types of matches that may be used in an LDAP search filter.
Example:
olcDbIndex: default pres,eq
olcDbIndex: uid
olcDbIndex: cn,sn pres,eq,sub
olcDbIndex: objectClass eq
The first line sets the default set of indices to maintain to present and equality. The second line causes the default (pres,eq) set of indices to be maintained for the uid attribute type. The third line causes present, equality, and substring indices to be maintained for cn and sn attribute types. The fourth line causes an equality index for the objectClass attribute type.
There is no index keyword for inequality matches. Generally these matches do not use an index. However, some attributes do support indexing for inequality matches, based on the equality index.
A substring index can be more explicitly specified as subinitial, subany, or subfinal, corresponding to the three possible components of a substring match filter. A subinitial index only indexes substrings that appear at the beginning of an attribute value. A subfinal index only indexes substrings that appear at the end of an attribute value, while subany indexes substrings that occur anywhere in a value.
Note that by default, setting an index for an attribute also affects every subtype of that attribute. E.g., setting an equality index on the name attribute causes cn, sn, and every other attribute that inherits from name to be indexed.
By default, no indices are maintained. It is generally advised that minimally an equality index upon objectClass be maintained.
olcDbindex: objectClass eq
Additional indices should be configured corresponding to the most common searches that are used on the database. Presence indexing should not be configured for an attribute unless the attribute occurs very rarely in the database, and presence searches on the attribute occur very frequently during normal use of the directory. Most applications don't use presence searches, so usually presence indexing is not very useful.
If this setting is changed while slapd is running, an internal task will be run to generate the changed index data. All server operations can continue as normal while the indexer does its work. If slapd is stopped before the index task completes, indexing will have to be manually completed using the slapindex tool.
olcDbLinearIndex: { TRUE | FALSE }
If this setting is TRUE slapindex will index one attribute at a time. The default settings is FALSE in which case all indexed attributes of an entry are processed at the same time. When enabled, each indexed attribute is processed individually, using multiple passes through the entire database. This option improves slapindex performance when the database size exceeds the BDB cache size. When the BDB cache is large enough, this option is not needed and will decrease performance. Also by default, slapadd performs full indexing and so a separate slapindex run is not needed. With this option, slapadd does no indexing and slapindex must be used.
olcDbMode: { <octal> | <symbolic> }
This directive specifies the file protection mode that newly created database index files should have. This can be in the form 0600 or -rw-------
Default:
olcDbMode: 0600
olcDbSearchStack: <integer>
Specify the depth of the stack used for search filter evaluation. Search filters are evaluated on a stack to accommodate nested AND / OR clauses. An individual stack is allocated for each server thread. The depth of the stack determines how complex a filter can be evaluated without requiring any additional memory allocation. Filters that are nested deeper than the search stack depth will cause a separate stack to be allocated for that particular search operation. These separate allocations can have a major negative impact on server performance, but specifying too much stack will also consume a great deal of memory. Each search uses 512K bytes per level on a 32-bit machine, or 1024K bytes per level on a 64-bit machine. The default stack depth is 16, thus 8MB or 16MB per thread is used on 32 and 64 bit machines, respectively. Also the 512KB size of a single stack slot is set by a compile-time constant which may be changed if needed; the code must be recompiled for the change to take effect.
Default:
olcDbSearchStack: 16
olcDbShmKey: <integer>
Specify a key for a shared memory BDB environment. By default the BDB environment uses memory mapped files. If a non-zero value is specified, it will be used as the key to identify a shared memory region that will house the environment.
Example:
olcDbShmKey: 42
示例条目
dn: olcDatabase=hdb,cn=config objectClass: olcDatabaseConfig objectClass: olcHdbConfig olcDatabase: hdb olcSuffix: "dc=example,dc=com" olcDbDirectory: /usr/local/var/openldap-data olcDbCacheSize: 1000 olcDbCheckpoint: 1024 10 olcDbConfig: set_cachesize 0 10485760 0 olcDbConfig: set_lg_bsize 2097152 olcDbConfig: set_lg_dir /var/tmp/bdb-log olcDbConfig: set_flags DB_LOG_AUTOREMOVE olcDbIDLcacheSize: 3000 olcDbIndex: objectClass eq
复制
为了提供一个有弹性的企业部署,复制目录是一个基础需求.
OpenLDAP有多种配置选项来建立一个可复制的目录. 在前一个版本里面, 复制被限定在一个主服务器和若干个从服务器的条件下来讨论。一个主服务器从其他客户端接受目录更新, 而一个从服务器则仅仅从一个(单个的)主服务器接受更新. 这个复制结构被僵化地定义并且任何典型的数据库只能完成一个单一角色,主或者从.
现在OpenLDAP支持一个更广泛的复制拓扑, 关于提供者和消费者的以下这些条件已经不推荐了: 一个提供者复制目录更新到消费者; 消费者从提供者接收复制更新. 不像僵化定义的主/从关系,提供者/消费者角色更加的流动化:一个接收复制更新的消费者可能传递给其它服务器的另一个消费者,所以一个消费者也可以同时成为一个提供者。而且,消费者不需要成为一个实际上的LDAP服务器;它也可以仅仅是一个LDAP客户端。
以下章节将描述复制技术和讨论各种可用的复制选项.
复制技术
LDAP同步复制
LDAP同步复制引擎, 简称syncrepl, 是一个消费方的复制引擎,能让消费者服务器维护一个抽取片断的影子副本. 一个syncrepl引擎以slapd的一个线程的方式驻留在消费者那里. 它建立和维护一个消费者复制,方法是连接一个复制提供者去执行初始化DIT内容载荷以及接下来的定期的内容拉取或及时根据内容变更来更新。
Syncrepl 使用LDAP内容同步协议(或简称 LDAP Sync) 作为复制同步协议. LDAP Sync 提供一个有状态的复制,它同时支持拉模式和推模式同步并且不要求使用历史存储. 在拉模式复制下消费者定期拉提供者服务器的内容来更新. 在推模式复制下消费者监听提供者实时发送的更新. 因为协议不要求历史存储, 提供者不需要维护任何它接收到的更新的日志. (注意syncrepl引擎是可扩展的,并支持未来新增的复制协议.)
Syncrepl通过维护和交换同步cookies来保持对复制内容的状态的跟踪. 因为syncrepl消费者和提供者维护它们的内容状态, 消费者可以拉取提供者的内容来执行增量同步,只要请求那些最新的提供者内容条目。 Syncrepl也通过维护复制状态方便了复制的管理. 消费者复制可以在任何同步状态下从一个消费方或一个提供方的备份来构建. Syncrepl能自动重新同步消费者复制到和当前的提供者内容一致的最新状态.
Syncrepl同时支持拉模式和推模式同步. 在它的基本的 refreshOnly 同步模式下, 提供者使用基于拉模式的同步,这里消费者服务器不需要被跟踪并且不维护历史信息. 需要提供者处理的定期的拉请求信息,包含在请求本身的同步cookie里面。为了优化基于拉模式的同步, syncrepl把LDAP同步协议的当前阶段当成它的删除阶段一样处理, 而不是频繁地回滚完全重载. 为了更好地优化基于拉模式的同步, 提供者可以维护一个按范围划分的会话日志作为历史存储. 在它的 refreshAndPersist 同步模式, 提供者使用基于推模式的同步. 提供者维护对请求了一个持久性搜索的消费者服务器的跟踪,并且当提供者复制内容修改的时候向它们发送必要的更新.
有了syncrepl, 如果消费者服务器有对被复制的DIT片断的适当的操作权限,一个消费者服务器可以建立一个复制而不修改提供者的配置并且不需要重新启动提供者服务器. 消费者服务器可以停止复制,也不需要提供方的任何变更和重启.
Syncrepl支持局部的,稀疏的和片断复制. 影子DIT片断由一个标准通用搜索来定义,包括基础,范围,过滤条件,和属性列表. 复制内容也受限于syncrepl复制连接的绑定用户的操作权限.
LDAP内容同步协议
LDAP同步协议允许一个客户端维护DIT片段的一个同步副本。LDAP同步操作的定义是一套控制,以及扩展LDAP搜索操作的其它协议元素。本节仅简单介绍LDAP内容同步协议。欲了解更多信息,请参阅RFC4533 。
LDAP同步协议支持拉和监听变更,通过定义两个各不相同的同步操作: refreshOnly和refreshAndPersist 。拉是由refreshOnly操作实现的。消费者使用一个LDAP搜索请求拉提供者,附带LDAP同步控制。消费者副本通过使用传回搜索到的信息实现拉取, 来从供应商副本同步。提供者在正常搜索时,搜索行动结束返回SearchResultDone,来表示完成搜索。监听是由refreshAndPersist操作实施的。顾名思义,它首先是一个搜索,如refreshOnly 。不是在返回所有目前搜索条件相匹配的条目后就完成搜索,而是同步搜索仍然保持供应商的持久化。随后供应商的同步内容更新产生额外的条目更新发送给消费者。
refreshOnly操作和refreshAndPersist操作的刷新阶段,可以在当前阶段或删除阶段执行。
在当前阶段,提供者发送自上次同步以来搜索范围内更新的条目给消费者。提供者发送更新的条目的所有请求的属性,不论它们改变与否。对于每个仍然保持不变范围的条目,提供者发送一个当前的消息,只包含条目的名称和代表"当前"状态的同步控制。当前消息不包含条目的任何属性。在消费者收到所有更新和当前条目之后,它能够可靠地确定新的消费者副本,通过增加那些条目供应商新增的条目,和替换那些供应商修改的条目,并删除消费副本中没有更新过也没有被提供者指定为"当前"的条目。
更新条目的传播在删除阶段和在当前阶段是一样的。提供者发送搜索范围内自上次同步以来更新的条目的所有请求的属性,给消费者。在删除阶段,无论如何,供应商为搜索范围内每个删除的条目发送一个删除消息,而不是发送当前消息。删除消息只包含条目的名称代表"删除"状态和同步控制。新的消费副本的决定可根据附加在SearchResultEntry的同步控制信息来增加,修改和删除条目。
如果LDAP同步提供者维护了一个历史存储,而且可以确定哪些条目的范围超出了自上次同步时间以来的消费者副本,供应商可以使用删除阶段。如果供应商不保持任何记录存储,无法从历史存储确定范围之外的条目,或存储的历史并不包括消费者的过时的同步状态,供应商应利用当前阶段。比起全部内容重载产生的同步通信来,使用当前阶段是更有效的。为了更好的减少同步他通讯量,LDAP同步协议还提供了一些优化,如标准化entryUUIDs的传输和一个单一syncIdSet讯息中传送多种entryUUIDs 。
在refreshOnly同步的结尾,在同步完成之后,提供者发送一个同步cookie到消费者,作为消费者副本的一个状态指标。当消费者向供应商请求下次的增量同步时,它将展示收到的Cookie。
当使用 refreshAndPersist同步时,提供者在刷新阶段的结尾发送一个同步Cookie,通过发送一个同步信息消息refreshDone =为TRUE 。它还发送一个同步的Cookie附加到同步搜索的持久化阶段产生的SearchResultEntry消息中。在持久化阶段,提供者还可以发送一个同步信息,包含同步的Cookie,在任何提供者要更新消费端状态指标的时候。
在LDAP同步协议,条目具有唯一的entryUUID属性值。它可以作为条目的一个可靠的标识符。条目的DN,另一方面,可随时间变化,因此不能被视为可靠的标识符。entryUUID附在每个SearchResultEntry或SearchResultReference上作为同步控制的一个部分。
Syncrepl细节
syncrepl引擎同时使用LDAP同步协议的refreshOnly和refreshAndPersist操作. 如果一个syncrepl规范存在于一个数据库定义中, slapd(8) 以一个 slapd(8) 线程的方式启动一个syncrepl引擎并规划它的执行时间表. 如果指定了refreshOnly操作, syncrepl引擎在一个同步操作完成之后将按间隔时间重新排程. 如果指定了refreshAndPersist操作, 引擎将保持激活并从提供者服务器处理持久性同步消息.
syncrepl引擎同时应用刷新同步的当前阶段和删除阶段. 可以在提供者服务器配置一个会话日志存储一定数量的从数据库中删除的entryUUIDs。多复制共享相同的会话日志. 如果会话日志是当前的并且消费者服务器足够新以至于在客户端的最后一次同步之后没有会话日志条目被删除,那么syncrepl引擎使用删除阶段. 如果没有为复制内容配置会话日志或如果消费者复制太陈旧而无法被会话日志涵盖到, syncrepl引擎使用当前阶段. 目前会话日志存储的设计是基于内存的, 所以包含在会话日志的信息相对多提供者的调用不是持久性的. 目前它不支持通过使用LDAP操作来操作会话日志存储. 它目前也不支持对会话日志施加访问控制.
作为进一步的优化, 甚至同步搜索都不和任何会话日志关联, 当没有发生复制相关的更新时将不会有任何条目传输给消费者.
syncrepl引擎, 是一个消费方的复制引擎, 可以工作在任何后端. LDAP同步提供者可以在任何后端配置成一个 overlay , 但是最好工作在 back-bdb 或 back-hdb 后端.
LDAP同步提供者为每一个数据库维护一个 contextCSN 作为提供者内容的当前同步状态指标. 它是提供者范围的最大 entryCSN,所以对于更小的拥有悬而未决的entryCSN值的条目来说不存在事务. contextCSN不能只是设成最大的已发表的entryCSN,因为 entryCSN 是在一个事务开始之前获得的并且事务还未提交到发表序列.
提供者在context suffix 条目的 contextCSN 属性存储 上下文的contextCSN . 这个属性不是在每个更新操作之后写入数据库; 而是主要在内存中维护. 在数据库启动时间提供者读取最后一次存储的 contextCSN 到内存里并且此后就只使用内存内的拷贝. 缺省的, 对 contextCSN 的变更作为一个数据库更新的结果将不写入数据库,直到服务器完全干净地关机. 如果需要的话,设置一个检查点可以让contextCSN写出得更频繁一些.
注意在启动的时间, 如果提供者不能从suffix条目读取一个 contextCSN , 它将扫描整个数据库来决定它的值, 并且在一个大的数据库中扫描可能要花很长时间. 当一个 contextCSN 值被读取, 这个数据库将仍被扫描用于任何高于它的 entryCSN 值, 以确保 contextCSN 值真的反应了数据库中entryCSN的最大提交 . 在支持不等式索引的数据库中, 在 entryCSN 属性上设置一个 eq 索引并配置 contextCSN 检查点,将极大地加速这个扫描步骤.
如果通过读取和扫描数据库没有决定 contextCSN, 一个新的值将被生成. 而且, 如果扫描数据库产生了一个比之前纪录在suffix条目中的contextCSN属性更大的entryCSN,一个检查点将立刻写入新的值.
消费者也存储它的复制状态, 它是作为一个同步cookie接收的提供者的contextCSN, 在suffix条目的contextCSN属性. 当它执行对提供者服务器的顺序增量同步时,由一个消费者服务器维护的复制状态被用作同步状态指标. 当它在一个级联复制配置中承当一个第二提供者服务器时,它也被用作提供方的同步状态指标. 因为消费者和提供者状态信息是在它们各自的服务器的同一个地方维护的, 任何消费者可以被提拔成为提供者(反之亦然)而不需要任何特别的动作.
因为在syncrepl规范中可能使用一个通用搜索过滤器, 上下文中的一些条目可能被从同步内容中省略了. syncrepl引擎建立一个粘条目来填充复制上下文中的窟窿,如果复制内容的任何部分属于这个窟窿的话。 这些粘条目在搜索结果中将不返回,除非提供了ManageDsaIT控制。
另外,作为在syncrepl规范使用搜索过滤器的结果, 可能会有类似这样的修改,即从复制范围移除一个条目,即使提供者上的条目还没有被删除。逻辑上这个条目必须在消费者服务器被删除但是在refreshOnly模式下,如果没有会话日志则提供者无法检测和传播这个变更.
关于配置,参见 Syncrepl 节.
部署替代
LDAP同步协议只对复制规定了狭窄的范围, OpenLDAP实现则是极为弹性的并且支持各种操作模式以处理协议中未显式地提出的其他情景.
Delta-syncrepl复制
- LDAP同步复制的缺点:
LDAP同步复制是一个基于对象的复制机制. 当提供者的一个被复制对象中的任何属性值改变时, 每个消费者在复制过程中撷取并处理完整的变更对象, 包括所有改变和没改变的属性值. 这方法的一个好处是当多个变更发生在单一对象上时, 那些变更的精确顺序不需要保存; 只有最终状态是有意义的. 但是当使用模式(匹配的方式)在一次变更中处理很多对象时,这个方法可能有缺点。
例如, 假设你有一个数据库包含 100,000 对象,每个对象是 1 KB . 进一步, 假设你经常运行一个批处理工作来变更主服务器上的 100,000 对象的每一个对象中的一个两字节的属性值. 不算LDAP和TCP/IP协议的开销, 每次你运行这个工作每个消费者将传送并处理 1 GB 的数据,只是为了处理这个 200KB 的变更!
在类似这样的案例中,99.98% 被传送和处理的数据将是多余的, 因为它们代表那些未变更的值. 这是一个对宝贵的传输和处理带宽的浪费并且可能导致发展出不可接受的复制日志的积压. 虽然这个情形是一个极端, 但它有助于演示某些LDAP部署的一个非常真实的问题.
- 看看Delta-syncrepl怎么处理:
Delta-syncrepl, 一个基于变更日志syncrepl变种, 被设计用来处理类似上面所说的情况. Delta-syncrepl通过在提供者一端维护一个可选择深度的变更日志来起作用. 复制消费者为它需要的变更检查这个变更日志,只要变更日志包含它需要的变更,消费者就从变更日志撷取这些变更并把它们应用到自己的数据库. 不过,一个复制(译者注:指变更日志里的变更)如果离上一次同步的状态太远(或消费者根本就是空的), 可以用常规的syncrepl把它(指消费者)恢复到最新的状态然后复制重新切换到delta-syncrepl模式.
关于配置请参考 Delta-syncrepl 章节.
N-Way Multi-Master复制
Multi-Master复制是一个使用Syncrepl复制数据到多个提供者(“主服务器”)目录服务器的复制技术.
对于Multi-Master replication有效的观点
- 如果任何提供者失败了, 其他提供者将继续接受更新
- 避免了单点失败
- 提供者们可以在不同的物理位置例如跨越全球网络.
- 好的自动容错/高可用性
对于Multi-Master replication无效的观点
(这些经常被声称是Multi-Master复制的优点但是那些说法是错误的):
- 它不关负载均衡任何事
- 提供者必须对所有其他的服务器进行写操作,这意味着分布在所有的服务器上的网络交通和写操作负载,和单一主服务器是一样的。
- 多服务器的服务器利用率和负载在最好的情况下和单服务器一样; 最坏的情况下单服务器更优,因为在提供者和消费者之间使用不同的模式的时候索引可以做出不同的优化调整.
和Multi-Master replication抵触的观点
- 打破了目录模式的数据一致性的保障
- http://www.openldap.org/faq/data/cache/1240.html
- 如果提供者的连接因为网络问题丢失了, 那么 "自动容错" 只会使问题复杂化
- 通常, 一个特定的机器不能区分失去和一个节点的联系是因为该节点崩溃了还是因为网络连接失败了a
- 如果一个网络是分割开的而多个客户端开始向每一个"主服务器"写操作,那么和解将是一个痛苦; 可能最好的办法是禁止那些被单一提供者分隔开的客户端的写操作
关于配置,请看下面的 N-Way Multi-Master 章节
MirrorMode复制
MirrorMode是一个混合配置,既提供单主服务器复制的所有一致性保障,也提供多主服务器模式的高可用性. 在 MirrorMode 两个提供者都被设置成从对方复制(就象一个多主服务器配置), 但是一个额外的前段被用来引导所有的写操作到仅仅到两台服务器中的其中一台. 第二个提供者将只在第一台服务器崩溃时进行写操作, 那时这个前端将切换路径引导所有的写操作到第二个提供者. 当一个崩溃的提供者被修复并且重启动后将自动从正在运行的提供者那里活得任何更新并重新同步.
MirrorMode的观点
- 对于目录的写操作提供了一个高可用性 (HA) 方案(复制处理读操作)
- 只有一个提供者是可操作的l, 写操作的安全是可接受的
- 提供者节点从对方互相复制, 所以它们总是最新的并且可以随时准备好接管 (热备份)
- Syncrepl也允许提供者节点在任何停机时间进行重新同步
和MirrorMode抵触的观点
- MirrorMode 不能被称为多主机方案. 这是因为同一时间写操作不得不仅限于镜像节点中的一个
- MirrorMode 可被称为Active-Active Hot-Standby(“双活热备份”,呃,这个翻译怎么样,传神不?), 因此需要一个额外的服务器(代理模式的slapd)或设备(硬件负载平衡装置)来管理哪个提供者是当前激活的
- 备份的管理稍微不同
- 如果备份bdb本身并且定期备份事务日志文件,那么镜像对的相同数字需要用于收集日志文件直到下一次数据库备份发生
- 为了确保所有数据库都是一致的, 当执行一个slapcat的时候每个数据库可能都不得不置于只读模式.
- Delta-Syncrepl扔不支持
关于配置,请看下面的 MirrorMode 章节
Syncrepl代理模式
因为LDAP同步协议同时支持基于“拉”和“推”的复制, “推”模式 (refreshAndPersist) 在提供者开始"推"变更之前仍必须由消费者初始化. 在一些网络配置中, 特别是防火墙限制了连接的方向时, 一个提供者初始化的推模式是需要的.
这个模式可以被配置成LDAP Backend (Backends and slapd-ldap(8)). 不用在实际的消费者服务器上运行syncrepl引擎, 而是一个slapd-ldap代理设置在靠近(或搭配在)提供者的地方指向消费者, 而这个syncrepl引擎运行在这个代理服务器上.
关于配置, 请看 Syncrepl代理 章节.
替代Slurpd
旧的slurpd机制只操作主服务器初始化的推模式. Slurpd复制被Syncrepl复制取代了并且在OpenLDAP 2.4中被完全移除了.
slurpd守护进程是原来继承自UMich's LDAP的复制机制并且以推模式操作: 主服务器推变更到从服务器. 因为多种原因它被替换掉, 简短的说:
- 它是不可靠的
- 它对replog中的记录的次序极为敏感
- 它可能很容易失去同步, 这时需要手工干预来从主目录重新同步从服务器数据库
- 它对不可用的服务器不是非常宽容. 如果一个从服务器长时间停机, replog可能变得太大以至于slurpd无法处理
- 它只工作在推模式
- 它需要停止和重新启动主服务器来增加从服务器
- 它只支持单一主服务器复制
- 它是不可靠的
Syncrepl没有那些弱点:
- Syncrepl是自同步的; 你可以在任何状态启动一个消费者数据库,从完全空的到完全同步的,它将自动做正确的事来完成和维护同步
- 它对变更发生的次序完全不敏感
- 它保障消费者和提供者内容的合流,不用手工干预
- 无论一个消费者多长时间没有联系提供者,它都能重新同步
- Syncrepl能双向操作
- 消费者能在不用碰提供者的情况下被加入
- 支持多主服务器复制
- Syncrepl是自同步的; 你可以在任何状态启动一个消费者数据库,从完全空的到完全同步的,它将自动做正确的事来完成和维护同步
配置不同的复制类型
Syncrepl
Syncrepl配置
因为syncrepl是一个消费方的复制引擎, syncrepl规范定义在 slapd.conf(5) 的消费者服务器, 而不是在提供者的服务器配置文件里. 复制内容的初始化装载可以有两种执行方式,以无同步cookie的方式启动一个syncrepl 引擎,或装载一个提供者服务器的全备份LDIF文件填充到消费者服务器.
当从一个备份装载的时候, 它不需要执行从提供者内容的最新备份初始化装载这个动作. syncrepl引擎将自动同步初始化的消费者复制当前的提供者内容. 结果是, 它不需要为了避免由于内容备份和装载过程中提供者服务器仍在更新而导致复制不一致的问题来停止提供者服务器.
当复制一个大规模的目录时, 特别是在一个带宽受限的环境, 建议从备份装载消费者而不是使用syncrepl执行一个完全的初始化装载.
设置提供者的slapd
提供者被实现为一个 overlay, 所以这个 overlay 本身在使用之前必须首先如 slapd.conf(5) 配置. 提供者只有两个配置指示, 在 contextCSN 上设定检查点和配置会话日志. 因为 LDAP 同步搜索受限于访问控制, 应为复制的内容设置正确的访问控制权限.
contextCSN检查点设置如下
syncprov-checkpoint <ops> <minutes>
检查点只在成功的写操作之后测试. 如果 <ops> 操作了或从上次检查点到现在超过了 <minutes> 时间, 将执行一个新的检查点.
会话日志设置如下
syncprov-sessionlog <size>
这里 <size> 是会话日志可以记录的条目的最大数量. 当一个会话日志被配置好, 它就自动用于所有对此数据库的 LDAP 同步搜索.
注意使用会话日志需要搜索 entryUUID 属性. 在这个属性上设一个 eq 索引将极有益于提供者服务器的会话日志的性能.
slapd.conf(5)中一个更复杂的例子内容如下:
database bdb
suffix dc=Example,dc=com
rootdn dc=Example,dc=com
directory /var/ldap/db
index objectclass,entryCSN,entryUUID eq
overlay syncprov
syncprov-checkpoint 100 10
syncprov-sessionlog 100设置消费者的slapd
在 slapd.conf(5) 的replica范围的数据库一节定义了syncrepl复制. syncrepl引擎是独立的后端并且可以使用任何数据库类型定义directive.
database hdb
suffix dc=Example,dc=com
rootdn dc=Example,dc=com
directory /var/ldap/db
index objectclass,entryCSN,entryUUID eq
syncrepl rid=123
provider=ldap://provider.example.com:389
type=refreshOnly
interval=01:00:00:00
searchbase="dc=example,dc=com"
filter="(objectClass=organizationalPerson)"
scope=sub
attrs="cn,sn,ou,telephoneNumber,title,l"
schemachecking=off
bindmethod=simple
binddn="cn=syncuser,dc=example,dc=com"
credentials=secret在这个例子中, 消费者将从ldap://provider.example.com的389端口连接到提供者 slapd(8) 来执行每天一次同步的拉操作(refreshOnly)模式. 它将以 cn=syncuser,dc=example,dc=com 绑定,以密码"secret"进行简单验证. 注意要在提供者服务器为cn=syncuser,dc=example,dc=com设置适当的访问控制权限以接收想要的复制内容. 另外提供者上的搜索限制必须足够高以允许同步用户接收请求内容完整的拷贝. 消费者使用 rootdn 写入它的数据库所以它总是有全部的权限来写所有的内容.
在上面的例子中同步搜索将在dc=example,dc=com的整个子树搜索 objectClass 是 organizationalPerson 的条目. 请求的属性是 cn, sn, ou, telephoneNumber, title, 和 l. schema 检查被关闭,这样当处理从提供者slapd(8)来的更新时消费者 slapd(8) 将不会强制对条目进行 schema 检查.
更多的详细信息参见 syncrepl 指示, 见本管理指南的slapd配置文件的syncrepl节.
启动提供者和消费者的slapd
提供者slapd(8)不需要重启. contextCSN将会根据需要自动生成: 它可能原来就包含在 LDIF 文件里, 由 slapadd (8) 生成, 在上下文中通过变更生成, 或当第一次 LDAP 同步搜索到达提供者时生成. 如果装载了一个之前不包含contextCSN的LDIF 文件, slapadd (8) 应使用 -w 选项来令它生成. 这将使服务器第一次运行时变得快一点.
当启动一个消费者 slapd(8) 时, 为了从一个特定的状态开始同步,它可能使用命令行参数 -c 即cookie选项,以提供一个同步cookie. cookie是一个逗号分隔的name=value对的列表. 目前支持的 syncrepl cookie 字段是 csn=<csn> 和 rid=<rid>. <csn>代表消费者复制的当前同步状态. <rid> 标识这个消费者服务器的一个本地消费者复制. 它用于把cookie关联到slapd.conf(5)中拥有匹配的复制标识的 syncrepl 定义. <rid>必须超过三位数. 命令行cookie会覆盖存储在消费者复制数据库中的同步cookie.
Delta-syncrepl
Delta-syncrepl提供者配置
设置 delta-syncrepl 需要同时改变主服务器和复制服务器的配置:
# 给予复制DN无限的读权限. 这个 ACL 需要和其他
# ACL 声明合并, 并且/或者在数据库范围内移动
# "by * break" 部分会执行随后的规则
# 细节请看 slapd.access(5) .
access to *
by dn.base="cn=replicator,dc=symas,dc=com" read
by * break
# 设置模块路径
modulepath /opt/symas/lib/openldap
# 装载 hdb 后端
moduleload back_hdb.la
# 装载操作日志 overlay
moduleload accesslog.la
#装载 syncprov overlay
moduleload syncprov.la
# 操作日志数据库定义
database hdb
suffix cn=accesslog
directory /db/accesslog
rootdn cn=accesslog
index default eq
index entryCSN,objectClass,reqEnd,reqResult,reqStart
overlay syncprov
syncprov-nopresent TRUE
syncprov-reloadhint TRUE
# 让复制 DN 有无限的搜索权限
limits dn.exact="cn=replicator,dc=symas,dc=com" time.soft=unlimited time.hard=unlimited size.soft=unlimited size.hard=unlimited
# 主数据库定义
database hdb
suffix "dc=symas,dc=com"
rootdn "cn=manager,dc=symas,dc=com"
## 任何期望的其他配置选项
# syncprov 特别索引
index entryCSN eq
index entryUUID eq
# 主数据库的syncrepl提供者
overlay syncprov
syncprov-checkpoint 1000 60
# 主数据库的操作日志overlay定义
overlay accesslog
logdb cn=accesslog
logops writes
logsuccess TRUE
# 每天扫描一次操作日志数据库, 并清除7天前的条目
logpurge 07+00:00 01+00:00
# 让复制DN有无限搜索权限
limits dn.exact="cn=replicator,dc=symas,dc=com" time.soft=unlimited time.hard=unlimited size.soft=unlimited size.hard=unlimited更多信息, 访问(slapo-accesslog(5) 和 slapd.conf(5))相关的 man 页
Delta-syncrepl消费者配置
# 复制数据库配置
database hdb
suffix "dc=symas,dc=com"
rootdn "cn=manager,dc=symas,dc=com"
## 任何关于复制的其他配置, 例如你期望的索引
##
# syncrepl特有的索引
index entryUUID eq
# syncrepl参数
syncrepl rid=0
provider=ldap://ldapmaster.symas.com:389
bindmethod=simple
binddn="cn=replicator,dc=symas,dc=com"
credentials=secret
searchbase="dc=symas,dc=com"
logbase="cn=accesslog"
logfilter="(&(objectClass=auditWriteObject)(reqResult=0))"
schemachecking=on
type=refreshAndPersist
retry="60 +"
syncdata=accesslog
# 提交更新到主服务器
updateref ldap://ldapmaster.symas.com以上配置假定你在你用于绑定到提供者的数据库中有一个复制者标识. 另外, 所有数据库 (主数据库, 复制数据库, 以及操作日志存储数据库) 也应该正确调整 DB_CONFIG 文件以满足你的需要.
N-Way Multi-Master
以下例子将使用三个主节点. Keeping in line with test050-syncrepl-multimaster of the OpenLDAP test suite, 我们将通过cn=config配置slapd(8)
这里设置配置数据库:
dn: cn=config objectClass: olcGlobal cn: config olcServerID: 1 dn: olcDatabase={0}config,cn=config objectClass: olcDatabaseConfig olcDatabase: {0}config olcRootPW: secret
第二和第三服务器明显会有一个不同的 olcServerID:
dn: cn=config objectClass: olcGlobal cn: config olcServerID: 2 dn: olcDatabase={0}config,cn=config objectClass: olcDatabaseConfig olcDatabase: {0}config olcRootPW: secret
这里设置 syncrepl 为提供者 (因为这些都是主服务器):
dn: cn=module,cn=config objectClass: olcModuleList cn: module olcModulePath: /usr/local/libexec/openldap olcModuleLoad: syncprov.la
现在我们设置第一个主节点 (使用你自己的确切的urls替换掉 $URI1, $URI2 和 $URI3 等.):
dn: cn=config changetype: modify replace: olcServerID olcServerID: 1 $URI1 olcServerID: 2 $URI2 olcServerID: 3 $URI3 dn: olcOverlay=syncprov,olcDatabase={0}config,cn=config changetype: add objectClass: olcOverlayConfig objectClass: olcSyncProvConfig olcOverlay: syncprov dn: olcDatabase={0}config,cn=config changetype: modify add: olcSyncRepl olcSyncRepl: rid=001 provider=$URI1 binddn="cn=config" bindmethod=simple credentials=secret searchbase="cn=config" type=refreshAndPersist retry="5 5 300 5" timeout=1 olcSyncRepl: rid=002 provider=$URI2 binddn="cn=config" bindmethod=simple credentials=secret searchbase="cn=config" type=refreshAndPersist retry="5 5 300 5" timeout=1 olcSyncRepl: rid=003 provider=$URI3 binddn="cn=config" bindmethod=simple credentials=secret searchbase="cn=config" type=refreshAndPersist retry="5 5 300 5" timeout=1 - add: olcMirrorMode olcMirrorMode: TRUE
现在启动主服务器和一个或多个消费者服务器, 也把上面的 LDIF 加入到第一个消费者, 第二个消费者等等. 然后它将复制cn=config. 你现在就在config数据库上拥有了多路多主机.
我们仍不得不复制实际的数据, 而不仅是 config, 所以添加下面这些到主服务器(所有激活的和配置好的消费者/主服务器将领取这个配置, 因为他们都是在同步的). 同样的, 以任何对你的安装可用的设置替换所有 ${} 变量:
dn: olcDatabase={1}$BACKEND,cn=config objectClass: olcDatabaseConfig objectClass: olc${BACKEND}Config olcDatabase: {1}$BACKEND olcSuffix: $BASEDN olcDbDirectory: ./db olcRootDN: $MANAGERDN olcRootPW: $PASSWD olcLimits: dn.exact="$MANAGERDN" time.soft=unlimited time.hard=unlimited size.soft=unlimited size.hard=unlimited olcSyncRepl: rid=004 provider=$URI1 binddn="$MANAGERDN" bindmethod=simple credentials=$PASSWD searchbase="$BASEDN" type=refreshOnly interval=00:00:00:10 retry="5 5 300 5" timeout=1 olcSyncRepl: rid=005 provider=$URI2 binddn="$MANAGERDN" bindmethod=simple credentials=$PASSWD searchbase="$BASEDN" type=refreshOnly interval=00:00:00:10 retry="5 5 300 5" timeout=1 olcSyncRepl: rid=006 provider=$URI3 binddn="$MANAGERDN" bindmethod=simple credentials=$PASSWD searchbase="$BASEDN" type=refreshOnly interval=00:00:00:10 retry="5 5 300 5" timeout=1 olcMirrorMode: TRUE dn: olcOverlay=syncprov,olcDatabase={1}${BACKEND},cn=config changetype: add objectClass: olcOverlayConfig objectClass: olcSyncProvConfig olcOverlay: syncprov
注意: 你的所有服务器始终必须使用例如 NTP http://www.ntp.org/, 原子钟, 或一些其他可用的时间参照物紧紧同步.
注意: 如slapd-config(5)指出的, 在 olcSyncRepl 指示中定义的 URLs 是从它们那里复制的服务器的 URLs. 这些必须准确地匹配 slapd 监听(命令行参数选项的 -h )的URLs . 否则 slapd 可能尝试从它自身复制, 而导致循环.
MirrorMode
镜像模式配置实际上非常容易. 如果你已经配置了一个普通的 slapd syncrepl 提供者, 那么唯一的改变就是以下两个参数:
mirrormode on
serverID 1注意: 你需要确保每个镜像的serverID是不同的并且把它作为一个全球配置选项.
Mirror Node配置
第一步是配置syncrepl提供者,就像 配置提供者slapd 一节写的那样.
注意: Delta-syncrepl还不支持镜像模式.
这里是从一个在refreshAndPersist模式下使用LDAP同步复制的例子中截取的片断:
镜像模式节点 1:
# 全球部分
serverID 1
# 数据库部分
# syncrepl参数
syncrepl rid=001
provider=ldap://ldap-sid2.example.com
bindmethod=simple
binddn="cn=mirrormode,dc=example,dc=com"
credentials=mirrormode
searchbase="dc=example,dc=com"
schemachecking=on
type=refreshAndPersist
retry="60 +"
mirrormode on镜像模式节点 2:
# 全球部分
serverID 2
# 数据库部分
# syncrepl参数
syncrepl rid=001
provider=ldap://ldap-sid1.example.com
bindmethod=simple
binddn="cn=mirrormode,dc=example,dc=com"
credentials=mirrormode
searchbase="dc=example,dc=com"
schemachecking=on
type=refreshAndPersist
retry="60 +"
mirrormode on它真的很简单; 每个镜像模式节点设置得完全一样, 除了 serverID 是唯一的, 并且每个消费者都被指向另一个服务器.
容错配置
这通常有两个选择; 1. 硬件代理/负载均衡 或 专用的代理软件, 2. 使用一个 Back-LDAP 代理作为一个 syncrepl 提供者
一个典型的企业例子可能是:
图 X.Y: 在一个双数据中心配置中使用镜像模式
标准消费者配置
这和设置消费者slapd一节完全一样. 可以设置一个普通的复制模式, 也可以使用 delta-syncrepl 复制模式.
MirrorMode总结
现在你将有一个目录架构提供单主服务器复制的全部一致性保障, 同时也提供多主服务器复制的高可用性.
Syncrepl代理
图片 X.Y: 取代slurpd
以下例子是一个自包含的推模式复制方案:
#######################################################################
# 标准 OpenLDAP 主/提供者(服务器)
#######################################################################
include /usr/local/etc/openldap/schema/core.schema
include /usr/local/etc/openldap/schema/cosine.schema
include /usr/local/etc/openldap/schema/nis.schema
include /usr/local/etc/openldap/schema/inetorgperson.schema
include /usr/local/etc/openldap/slapd.acl
modulepath /usr/local/libexec/openldap
moduleload back_hdb.la
moduleload syncprov.la
moduleload back_monitor.la
moduleload back_ldap.la
pidfile /usr/local/var/slapd.pid
argsfile /usr/local/var/slapd.args
loglevel sync stats
database hdb
suffix "dc=suretecsystems,dc=com"
directory /usr/local/var/openldap-data
checkpoint 1024 5
cachesize 10000
idlcachesize 10000
index objectClass eq
# 其它索引
index default sub
rootdn "cn=admin,dc=suretecsystems,dc=com"
rootpw testing
# syncprov特有的索引
index entryCSN eq
index entryUUID eq
# 主数据库的syncrepl 提供者
overlay syncprov
syncprov-checkpoint 1000 60
# 让复制DN 有无限的搜索权限
limits dn.exact="cn=replicator,dc=suretecsystems,dc=com" time.soft=unlimited time.hard=unlimited size.soft=unlimited size.hard=unlimited
database monitor
database config
rootpw testing
##############################################################################
# 消费者代理,它通过Syncrepl拉数据并且通过slapd-ldap推数据
##############################################################################
database ldap
# 忽略其他数据库的冲突, 因为我们需要推同样的后缀
hidden on
suffix "dc=suretecsystems,dc=com"
rootdn "cn=slapd-ldap"
uri ldap://localhost:9012/
lastmod on
# 我们不需要对这个DSA做任何操作
restrict all
acl-bind bindmethod=simple
binddn="cn=replicator,dc=suretecsystems,dc=com"
credentials=testing
syncrepl rid=001
provider=ldap://localhost:9011/
binddn="cn=replicator,dc=suretecsystems,dc=com"
bindmethod=simple
credentials=testing
searchbase="dc=suretecsystems,dc=com"
type=refreshAndPersist
retry="5 5 300 5"
overlay syncprov这种类型的一个复制配置可能是这样的:
#######################################################################
# 标准 OpenLDAP 无 Syncrepl的从服务器
#######################################################################
include /usr/local/etc/openldap/schema/core.schema
include /usr/local/etc/openldap/schema/cosine.schema
include /usr/local/etc/openldap/schema/nis.schema
include /usr/local/etc/openldap/schema/inetorgperson.schema
include /usr/local/etc/openldap/slapd.acl
modulepath /usr/local/libexec/openldap
moduleload back_hdb.la
moduleload syncprov.la
moduleload back_monitor.la
moduleload back_ldap.la
pidfile /usr/local/var/slapd.pid
argsfile /usr/local/var/slapd.args
loglevel sync stats
database hdb
suffix "dc=suretecsystems,dc=com"
directory /usr/local/var/openldap-slave/data
checkpoint 1024 5
cachesize 10000
idlcachesize 10000
index objectClass eq
# 其它索引
index default sub
rootdn "cn=admin,dc=suretecsystems,dc=com"
rootpw testing
# 让复制DN拥有无限的搜索权限
limits dn.exact="cn=replicator,dc=suretecsystems,dc=com" time.soft=unlimited time.hard=unlimited size.soft=unlimited size.hard=unlimited
updatedn "cn=replicator,dc=suretecsystems,dc=com"
# 提交更新到主服务器
updateref ldap://localhost:9011
database monitor
database config
rootpw testing你能看到我们在这里使用了 updatedn 参数,而它的示范 ACLs (usr/local/etc/openldap/slapd.acl) 可能如下:
# 给复制DN无限的读权限. 这个ACL可能需要和其他ACL声明配合.
#
access to *
by dn.base="cn=replicator,dc=suretecsystems,dc=com" write
by * break
access to dn.base=""
by * read
access to dn.base="cn=Subschema"
by * read
access to dn.subtree="cn=Monitor"
by dn.exact="uid=admin,dc=suretecsystems,dc=com" write
by users read
by * none
access to *
by self write
by * read为了支持更多的复制, 只要加入更多的数据库 ldap 节并相应增加 syncrepl rid 号码.
注意: 你必须以相同的数据填充主目录和从目录, 而不是像使用普通Syncrepl时候那样
如果你没有修改主目录配置的权限,你可以配置一个独立的ldap代理, 它看起来像这样:
图片 X.Y: 以一个独立版本取代 slurpd
以下配置是一个独立的LDAP代理的配置示例:
include /usr/local/etc/openldap/schema/core.schema
include /usr/local/etc/openldap/schema/cosine.schema
include /usr/local/etc/openldap/schema/nis.schema
include /usr/local/etc/openldap/schema/inetorgperson.schema
include /usr/local/etc/openldap/slapd.acl
modulepath /usr/local/libexec/openldap
moduleload syncprov.la
moduleload back_ldap.la
##############################################################################
# 消费者代理,通过Syncrepl拉数据并通过slapd-ldap推数据
##############################################################################
database ldap
# ignore conflicts with other databases, as we need to push out to same suffix
hidden on
suffix "dc=suretecsystems,dc=com"
rootdn "cn=slapd-ldap"
uri ldap://localhost:9012/
lastmod on
# 我们不需要对这个DSA做任何操作
restrict all
acl-bind bindmethod=simple
binddn="cn=replicator,dc=suretecsystems,dc=com"
credentials=testing
syncrepl rid=001
provider=ldap://localhost:9011/
binddn="cn=replicator,dc=suretecsystems,dc=com"
bindmethod=simple
credentials=testing
searchbase="dc=suretecsystems,dc=com"
type=refreshAndPersist
retry="5 5 300 5"
overlay syncprov如你所见, 使用Syncrepl和slapd-ldap(8) 剪裁你的复制来满足你的特有的网络拓扑,你可以让自己的想象力变得很疯狂.